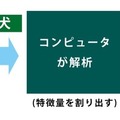



実用化が進められている人工知能関連技術「ニューラルネットワーク」、なかでも「ディープラーニング」は多くのシステムで導入が始まり、成果が期待される段階に入っています。
しかし、「それがどんな技術なのか?」「なぜ急速に進化したのか?」「そのしくみがまだ解らない」という人も多いのではないでしょうか。そろそろきちんと理解しておきたい時期ですよね。
ということで、東京大学発のベンチャー企業「シーエイトラボ」(C8Lab)社のCEOをつとめる新村拓也氏に機械学習やAI技術について聞き、この記事を”文系にもわかるニューラルネットワーク/ディープラーニング入門”としてまとめてみました。
なお、シーエイトラボ社はマーケティングやユーザの行動分析を主に行ってきた会社です。現在はニューラルネットワークを使った技術やシステムの開発に注力していて、新村氏はGoogle が無料で提供しているディープラーニングのライブラリ「Tensorflow」(テンソルフロー)の勉強会で講師を務めるなど、研究を発表したり啓蒙活動もおこなっています。
※「Tensorflow」はGoogleが公開しているディープラーニングを活用した機械学習ライブラリ。オープンソースなので開発者は無料で利用することができます。
シーエイトラボについて
神崎(編集部)
機械学習やニューラルネットワーク(NN)、ディープラーニング(DL)の話をお伺いする前に、シーエイトラボの仕事内容について教えてください。
新村(敬称略)
「機械学習」を専門にやる会社としてはじめたわけではなく、去年の年頭くらいから本格的に開発の着手をはじめました。それまでは一般的なウェブやAndroidアプリの開発が中心で、主にマーケティング分析、POSデータなどのビッグデータの分析、TwitterなどSNSの情報解析、ユーザの趣味趣向を分析するエンジン等の開発を行ってきました。ここ最近のAIブームと、ディープラーニングが実用的になってきたこともあって、いまは注力しています。
神崎
現在、シーエイトラボのホームページには「Halu」と「企業診断士」が紹介されていますね。
新村
「Halu」はビッグデータの解析やデータマイニングシステムです。「企業診断士」は、Twitterに投稿されたつぶやきを集計し、話題になっている企業をランキング形式で表示、企業名とともに商品サービスや話題のキーワードも抽出して表示することができるAndroidアプリです。試験的に運営していましたが現在、メンテナンス中です。どちらにもディープラーニングは使ってはいません。ただ、広義の機械学習の技術は使っていると言えるかもしれませんね。
ディープラーニングは受注開発を含めて、進行中の案件で使っています。
神崎
どのような分野で使われるものにディープラーニングを導入しているんですか
新村
いくつか取り組んでいますが、そのひとつが「姿勢計測」です。ある画像を解析して、被写体とカメラの距離や相対角度(被写体をどのような角度から見ているのか)といった情報を解析するシステムです。その他には株価のように連続で変化していく数値を予測するシステム等をディープラーニングで開発しています。よく「分類問題」と「回帰問題」という分けかたをしますが、「回帰問題」系の仕事が増えている印象です。
神崎
機械学習が活用される用途に「回帰問題」が増えているということですね。

新村氏はそう説明して、上のスライドを見せて説明してくれました。私はデジタルカメラのしくみについて書籍を執筆していますので、ロール、ピッチ、ヨーの意味くらいはわかりますが、それでもディープラーニングがどうやって計測して、どうして精度が高くなるのかは、残念ながらピンと来ません。初歩から理解していった方がよさそうです。
まずは「機械学習」について勉強していきましょう。
機械学習とは?
神崎
機械学習、ニューラルネットワークとディープラーニング…もっともホットな3つのキーワードの関係から教えてもらえますか。
新村
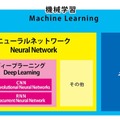
「機械学習」とは人間が学習するのと同様に、機械自身に学習させる方法や技術、そのアルゴリズム等をさします。その機械学習の手法のひとつに脳を模倣した「ニューラルネットワーク」があります。ニューラルネットワークでは特徴量のベクトル値を算出して考えたり、解析したりして一定の答えを出すんですが、最近話題になっている「ディープラーニング」は単にニューラルネットワークを多層にしたものです。
新村氏は「機械学習」と「ニューラルネットワーク」(NN)、「ディープラーニング」(DL)の関係について下記の図を書いてくれました。
最近話題になっている人工知能関連技術の大枠として「機械学習」があり、その中の脳の神経細胞をシュミレートしたNN、ディープラーニングなど、多くのAI関連のキーワードがあります。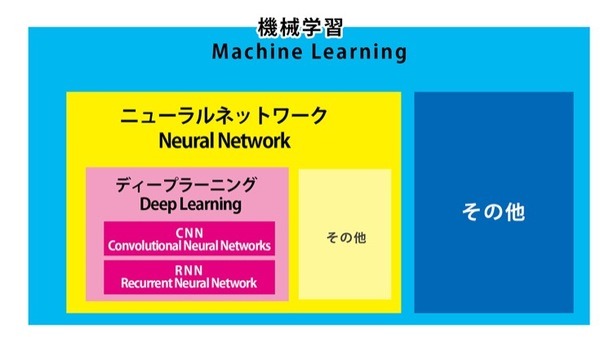
神崎
ディープラーニングでは「畳み込みニューラルネットワーク」という言葉も聞かれるようになりました。
新村
「畳み込み」はコンボリューショナル・ニューラル・ネットワークで使われていて「CNN」と略されています。ディープラーニングが抱えている課題、「過学習」を解決するのにも有効です。また、リカレントニューラルネットワーク(再帰型ニューラルネットワークと訳す)「RNN」も注目されていますので、今後は気にしてみると良いのではないでしょうか。
神崎
わかりました。CNNは後ほど解説をよろしくお願いします。
Googleの「AlphaGo」(アルファ碁)の囲碁決戦で、機械学習とディープラーニングが更に注目されましたね。
新村
ディープラーニングの考え方やメリットは昔からあったのですが、課題があってなかなか効果が出せなかったんです。しかし、その課題をクリアする方法が解ってきて、「Googleの猫」をきっかけに開発者の注目が集まり、「AlphaGo」で具体的な成果が一般に確認されると、一気に注目されるようになりました。Googleの「Tensorflow」など、技術者が無料で利用できるライブラリが提供され始めたこともあると思います。
AlphaGoで注目したい点は「強化学習」と「ニューラルネットワーク」を組み合わせたこと。強化学習とニューラルネットワークを組み合わせて、2手先、3手先といった先を読んだ思考をします。現在の状況に対して次の自分の一手はこれが有効だ、という回答を出すことはもちろん、自分がその手を打った場合、相手は次の手でこう返すだろう、そうしたら次の次の手ではどう返すべきか、という先読みを行った上で最適な回答を出します。次の一手だけでもたくさんの選択肢があるのに、更に次の手を先読みして推理するとその数はネズミ算式に増えていきます。それでもそれを推理して最良の一手を導き出すのです。
Googleの猫とニューラルネットワーク
機械学習が話題になったきっかけのひとつは、Googleが発表した「Googleの猫」です。「Googleの猫」は2012年、米グーグルの研究チーム「Google X Labs」(当時)が、機械学習の画像認識研究の成果とともに発表した画像のことです、ウェブやYouTUBEにある膨大な画像データをコンピュータに与えて一週間自律的に学習させたところ、「猫」の存在を学習したとされています。これには、人間の脳のしくみを模倣したニューラルネットワークの技術が使われていたので、ニューラルネットワークが一躍注目されることになりました。
Google DeepMindとディープラーニング
ディープラーニングを一躍有名にした出来事は2010年に起業したDeepMind社が2015年にネイチャー誌に発表した論文です。DeepMind社が開発したゲーム用自律学習型汎用AIシステム「DQN」はブロック崩しやパックマン等のテレビゲームを人間の上達者より上手にこなします。しかも、人間がやり方を教えたり、プログラミングしなくても、ゲームの操作方法やルールをDQNが試行錯誤して自分で学習する能力を持ちます。そこで使われている技術が「ディープラーニング」でした。この論文を見たGoogleによって同社は買収され、Google AI研究の開発機関のひとつになりました。今年の3月に話題になった世紀の囲碁対決で人間を破った人工知能「AlphaGo」もGoogle DeepMindが開発したシステムです。
神崎
さきほど触れた「分類問題」と「回帰問題」とはなんでしょうか。
新村
機械学習の用途には「分類問題」と「回帰問題」があります。「分類問題」は文字通り何かを分類することです。例えば、画像認識ならスキャンした画像が何であるか、「これは猫です」「これはお茶です」と識別する、その分類です。テキストならSPAMメールの検出、ニュースのジャンル分け、データ分析なら売れ筋商品やリコメンド商品の分類などがほんの一例です。分類問題は予測対象が犬、ネコなどの離散値である問題ということに対して、「回帰問題」は予測対象が1.05m、40.14$などの実数値である問題のことです。計算によって算出される数値、推測や未知のデータの予測など、更に時系列で変化する株価データなどです。
ニューラルネットワークの基本を解説するのに「分類問題」を例にすると解りやすいと思います。たくさんの画像を「犬」と「猫」に分類する、そんな解りやすい分類問題を例にしてニューラルネットワークを解説してみましょう。
ニューラルネットワークのすごいところ
機械学習のニューラルネットワークについて説明します。
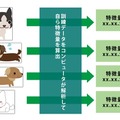
下図が分類問題のシンプルな例です。いくつかの画像を見て、「犬」と「猫」に分類してください。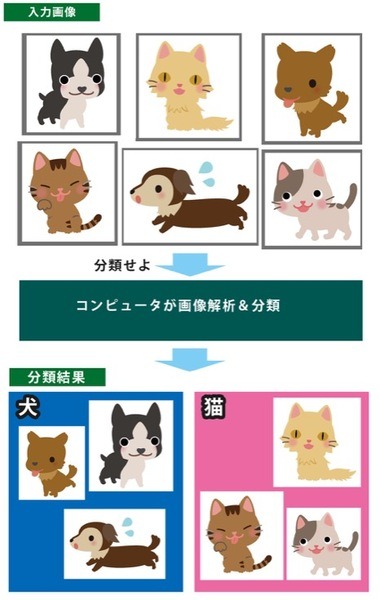
画像認識で成果を上げているディープラーニングでは、このような分類問題は得意分野になりつつあります。では、機械学習のニューラルネットワークでやるとこれのどの部分がすごいのでしょうか?
ニューラルネットワークがほかと異なるところは、膨大な学習によって、分類する要素を機械自身に発見させるところです。例えば、この犬と猫を分類する問題を皆さんが出されたとすると、犬と猫の区別をどうやって行いますか? どこを見て犬か猫かを判別するでしょうか? もう一度、画像を見てじっくり考えてみてください。
どうやって判別しているでしょうか?
犬にも猫にもたくさんの種類があって形状は様々です。ただ、耳が垂れていると犬っぽい、カラダが長い犬の種類がある、黒目が縦長だと猫っぽい、など、実際にはどことなく何かしらの特徴から判断して、人間は犬か猫かを区別しています。しかし、どこを見たら区別できるの? と、あらたまって区別の方法やそのルールを問われると「そ・・そりゃあ、あれでしょ(苦笑)・・うーん、見れば解るでしょ?」なんて答えるかもしれませんね。これは人間の脳が、今までの経験からそれが犬なのか猫なのかを判断するためのなんらかの「特徴」を学習していて、それをもとに判別していることを意味しています。
実はこれが重要なのです。今までのシステムでは犬か猫かをコンピュータが選別するためのルールを人間が指定していました。これをルールベース等と呼びます。しかし、イラストのように犬か猫かを選別する方法を定義することはとても難しいですよね。
機械学習のニューラルネットワークでは、識別して分類するために人間が提示したルールではなく、「ある “特徴量” を算出」してそれを使って分類します。その特徴量は訓練学習によって機械自身がみつけて学習したものです。「犬」の特徴量を算出することで、犬にはいろいろなパターンがあることを学習します。コンピュータが扱っている特徴量は実際には数値なのですが、ニュアンスとしては人間の「犬か猫かは見れば解る」と同様の特徴を訓練によって自分でみつけて学習します。開発者にとっては細かなルールを定義する必要から解放され、機能的には「なんとなく解るでしょ?」という曖昧な「特徴量」を学習できる可能性を持っているのです。
こうして完成した分類システムに画像を入力すると、その画像の特徴量を分析し、犬の特徴量の範囲と合致していれば犬であると判断し、猫の特徴量とが合致していれば猫と判断して分類するというわけです。そして、繰り返しますが、重要なのは犬の判断基準 (特徴量)は人間が作って与えたものではなくて、機械が学習によって自分で割り出したものなのです。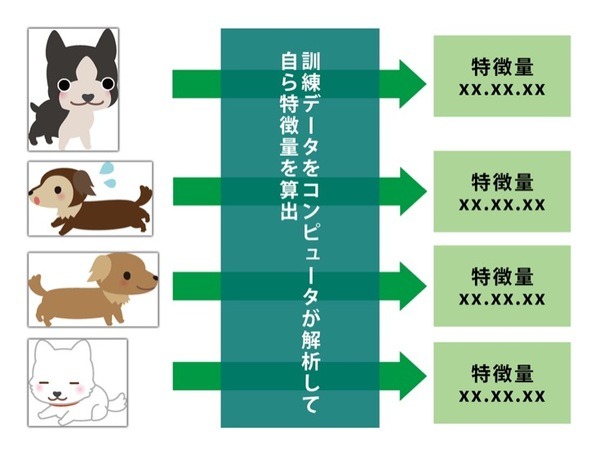
どうやって機械に学習させるのか?
機械はどうやって学習しているのでしょうか?
代表的な学習の仕方が、機械に質問と回答を同時に教える方法です。上の例で言えば、犬の画像に「分類は犬である」という正解を付けて分析させます。これをラベル付きデータと呼びます。
では、正解が解っているのに機械は何を分析するかというと「どうしてそれが犬に分類されるのか?」というところを考えさせるのです。つまり機械に「特徴量」を算出させる…機械に自ら特徴を発見させるというのは、そういうことなのです。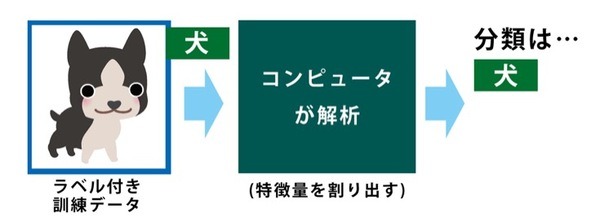
上記の例の画像を一枚解析して特徴量を覚えただけのとき、ほかの犬の画像を次に入力しても、同じ犬だとはほぼ分類できません。しかし、犬のラベル(正解)付きデータ画像を、仮に1000万枚読み込ませて訓練したとしたら、少なくても1000万通りの犬の特徴量を学習することになります。そうなれば、分類問題として、ラベルなしの犬の画像を入力して分類させたとき、膨大な特徴量から照合して、きちんと犬だと識別できる確率は高くなる気がします。
これが機械学習のニューラルネットワークの勉強法(のひとつ)であり、学習するためには膨大なビッグデータが必要になる理由です。
ここまで機械学習の分類問題を例に概要を解説しましたが、次回はもう少し具体的なところを、更に掘り下げてみましょう。新村氏がTensorflow勉強会で発表した「言語AI」(チヤットボット)の実験にもスポットをあてます。変数や公式が出てこない、文系でも解るやさしい解説にご期待ください。
また、わたし神崎は、今回のように人工知能の技術をやさしく解説し、ビジネス活用事例を紹介する書籍を現在執筆中です。出版されたらこのコラムでもご案内しますので、そちらも是非ご期待ください。
【追記】発売されました!「図解入門 最新 人工知能がよ~くわかる本」です。
「人工知能の最新情報とビジネス活用を網羅した書籍「図解入門 最新人工知能がよ~くわかる本」が発売」
東大発ベンチャーC8Labに聞く(3) 「ディープラーニング超入門 多層や畳み込みのしくみ」
東大発ベンチャーC8Labに聞く(2) チャットボットのしくみと会話AI試作と課題
東大発ベンチャーC8Labに聞く(1) 機械学習とニューラルネットワーク超入門