
オルツは、2024年6月18日に自由民主党本部にて行われた、平井卓也衆議院議員が本部長を務める同党のデジタル社会推進本部に参加した。
参加した自民党のデジタル社会推進本部では、オルツが目指すパーソナルAIの将来像に関してCEOの米倉千貴氏やCFOの日置友輔氏のデジ…


目覚ましい進化を遂げる一方、様々な分野で議論を巻き起こしているAI。先の見えない未来の技術と共存するべく、声を生業とする声優・梶裕貴氏が、自身の声をオフィシャルに活用できる音声合成ソフトを発表した。梶裕貴氏は『進撃の巨人』のエレン・イェーガー役などで知…

代表取締役社長 CEO/CTOを大阪大学の石黒浩氏がつとめるAVITA株式会社は、同社が提供しているアバターオンライン接客サービス「AVACOM」において、リアルタイム翻訳できる「翻訳機能」をリリースした。
「AVACOM」では、これまでも多言語対応可能なスタッフの手配サ…

京セラドキュメントソリューションズジャパン株式会社は、話した言葉をリアルタイムに認識して文字や図解、翻訳を表示するシステム「Cotopat Screen」が、福岡県警察の自動車運転免許試験場4施設(福岡、北九州、筑豊、筑後)に採用され、運用が開始されたことを発表した…
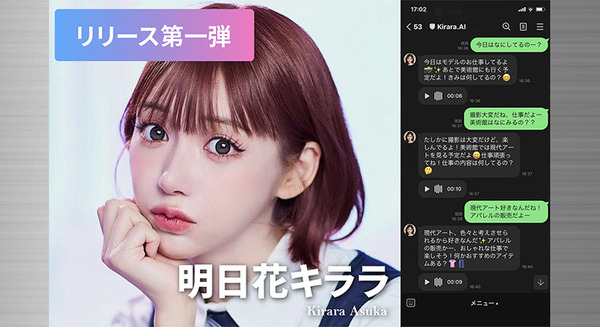
neverspaceは、実在する芸能人やインフルエンサーとAIなどを用いて疑似的な会話を体験できるサービス「Communicaiton.AI」の提供を2024年3月29日より開始。その第一弾として、タレントの明日花キララさんとLINE上で会話ができるAIコミュニケーションサービス「Kirara.AI…
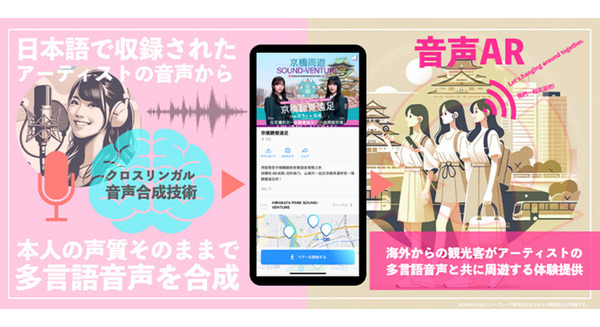
NTT西日本は、アーティストやアニメ等の音声価値に着目し、位置情報と音声情報を組み合わせ、特定の場所に行けば、設定された音声が流れる「音声AR」を活用した「日本のエンターテイメントのグローバル展開」と「旅行者の観光体験や楽しみ」両方の拡大をめざす実証実験…

エーアイは技術提携先であり、自動車を含むコネクテッドモビリティの世界へ独自のソリューションを提供し、感動的なユーザー体験を創出するグローバル・リーダーであるCerence Inc.(セレンス)が提供する超小型音声認識エンジン(Input AI Lite)・オーディオ信号処理…

AIポータルメディア「AIsmiley」を運営するアイスマイリーは、各業界のDX推進の支援の一環として合計161サービスの音声認識AIの製品、サービスをまとめた「音声認識AIカオスマップ2024」を2024年2月6日に公開した。
カオスマップ作成の背景
近年、OpenAI社のChatGPT…

NTTドコモは、デジタル分身のプロトタイプをメタコミュニケーションサービス「MetaMe」上に実装したデモを、2024年1月17日から東京国際フォーラムにて開催された「docomo Open House’24」で展示した。冒頭の画像は「邪神ちゃんドロップキック」のキャラクターの分身を…

ピカブルは、VTuber事務所『ななはぴ』とのVTuberの海外展開における協業を開始すると発表した。
この協業は『ななはぴ』所属VTuberの海外ファン層拡大を目的とし、ピカブルが提供する多言語吹替サービス『ファンボイス翻訳』を活用することで、海外のファン層に向けた…

ポケトーク株式会社は「ポケトーク for BUSINESS 同時通訳」ウェブブラウザ版の提供を開始することを2023年11月9日に発表し、同日に提供を開始した。
ウェブブラウザで使えるようになることで、一般のスマホやタブレットで自動翻訳機能が使用できるようになり、翻訳デ…


AI技術の進歩はクリエイティブ分野やビジネス、教育、研究など多岐にわたり注目されている。
その中でも、音声認識やテキスト変換の技術は大きく進展しており、実際の会議などの音声をテキスト化・マインドマップ化することで、議事録の作成などの労力を削減することが…