
デルはGPUと各種ディープラーニングのフレームワークにフォーカスし、性能を比較したパフォーマンス結果を公式ホームページ(TechCenter)内で公開した。1月17日に東京高田馬場でNVIDIAが開催した「DEEP LEARNING INSTITUTE」でも、ミニシアターでこの結果を公表している。また、詳細のレポートをPDFファイルとしてダウンロード可能だ。
主に、「GPUを使うとどの程度のパフォーマンスアップに繋がるのか」「複数枚数のGPUボードを使用する場合、数が多いほど速度向上の効果が現れるか」「Caffe、MXNet、TensorFlowなどのディープラーニング・フレームワークによってパフォーマンスの違いがあるか」などが見てとれるものとなっている。
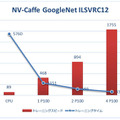
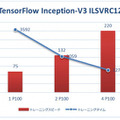
例えば、下記はディープラーニング・フレームワーク「NV-Caffe」(NVIDIA フォークの Caffe)で GoogleNet ニューラルネットワークの訓練速度と時間を比較したグラフ。「NVIDIA Tesla P100 GPU」をひとつ追加して最大5.3倍、4つで最大19.7倍の高速化という結果が出ている。
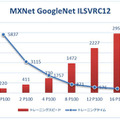
その他、「MXNet」を使って「NVIDIA Tesla P100 GPU」を16基まで増やしていった際のパフォーマンスや、TensorFlowを使用した場合等も紹介されている。


なお、複数のノードで TensorFlow を使用したトレーニングの場合、実行できたもののパフォーマンスは低下したとのこと。原因は調査中のため詳細情報は伏せている。
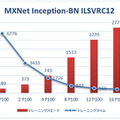
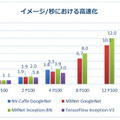
最後のグラフは、さまざまなディープラーニング・フレームワークで、複数の P100 GPU を使用する場合の高速化が確認できたもの。
なお、このレポートでは最後に下記のように実際の現場を想定した感想が付け加えられている。
実際のところ、リアルユーザアプリケーションではモデルをトレーニングするのに数日または数週間かかります。
ベンチマークのケースでは数分または数時間で実行されますが、実際にネットワークをトレーニングするために必要とされるのは、もっと時間がかかる実行からの小さなスナップショットです。例えば実際のアプリケーションのトレーニングには、120 万イメージにつき90 エポックが必要となります。P100 GPU を搭載した Dell C4130 では1 日とかからずに結果を出すこと可能ですが、CPU では1 週間以上かかります。これはエンドユーザにとって本当に利点となります。実際の使用事例による効果は、秒単位ではなく実行毎に数週間の時間を節約出来ることです。
「DEEP LEARNING INSTITUTE」イベントにおいて、ミニシアターでこのレポートを紹介したデルの日本法人は、下記のようにコメントしている。
現在は当社も他社も標準的な技術を使ってシステム構成するのが主体かと思う。デルは従来からの経験や知見を活かしたシステムの構成を行い、標準的な技術を使っていてもプロダクションシステムで動作させたときにも最適な構成を提案でき、障害時の対応も充実させている。






