
2018年4月9日、Google Cloud Platformブログにて「Cloud Speech-to-Text」サービスの大規模なアップデートが発表された。これは音声をテキストに変換するクラウドサービスで注目すべき新機能がいくつか追加されているので紹介したい。
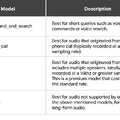
用途別の音声トランスクリプションモデル
認識精度を向上させるために、音声トランスクリプションが4つ選べるようになった。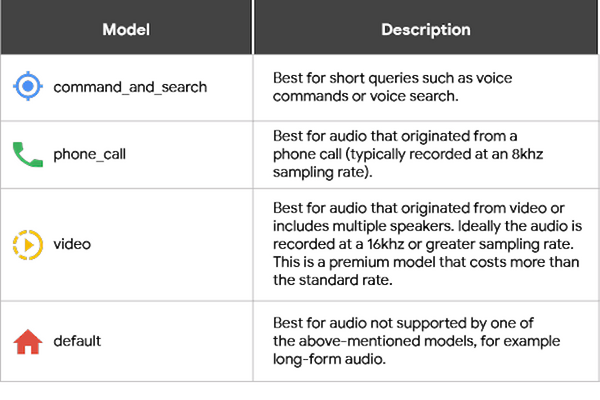
コマンド・サーチ、電話、ビデオ、デフォルトの4種類が用意されており、元音声がどの音声モデルなのかを利用者が指定することができる。これにより音声認識のエラーが54%~64%も減少するという。
自動句読点付与
音声認識した結果のテキストに自動的に句読点を付ける機能も大幅にアップデートされた。

長文にカンマ、ピリオド、疑問符などを挿入することで、読みやすいテキストを生成することができる。
認識メタデータでユースケースを記述
このサービスの利用者は、音声認識時にメタデータを任意に付与することができる。例えば、ショッピングアプリの音声コマンド、スポーツTVのバスケットボール番組などのタグを指定する。これらのメタデータが蓄積されることでGoogleが音声認識の開発の優先順位を判断したり、認識精度を向上させやすくなるという。
「Cloud Speech-to-Text」サービスの利用料金は、ビデオモデルを除くすべてのモデルで15秒間に0.006ドル、ビデオモデルの場合、15秒間に0.012ドルとなる。なお、5月31日までは試用期間としてビデオモデルも15秒間に0.006ドルで提供される。