富士通株式会社は2025年12月2日(火)、現実世界の物理法則を理解したAIであるフィジカルAIの研究成果として、人とロボットの相互作用を予測できる空間World Model技術を開発したと発表した。
同技術により、空間内の人・ロボット・物体の未来の状態を予測し、従来困難であった人とロボットの協調動作や複数ロボット間の最適な協調動作を実現する。同社は2026年1月6日(月)から1月9日(木)まで米国ラスベガスで開催されるCES2026にデモ出展する予定だ。
フィジカルAI研究の課題と富士通の強み
近年のAI技術の進歩により、デジタル空間で発展してきたAIを現実世界に展開する動きが活発化している。特にAIに物理法則を学習させて自律行動させるフィジカルAIの研究が盛んになっており、自動運転やスマートファクトリーなど実空間での様々な課題を解決する鍵として期待されている。
しかし現在のフィジカルAIは、通路が規定された製造現場や物流倉庫など整備された環境での活用が中心だ。人が生活する住宅やオフィスでは、人の動きが予測困難で物の配置も頻繁に変化するため空間の状況把握が難しく、適応が困難という課題がある。また多数の人やロボットが共存する環境では、他者がどう動くのか次の行動を予測できず、協調動作を実現することが難しいのが現状。
富士通はこれまで商業施設での人流解析、防犯分野での異常行動検出など、空間を把握するコンピュータビジョン技術を発展させてきた。さらに人と協調して自律的に業務を推進する「Fujitsu Kozuchi AI Agent」など、デジタル領域でのAI技術を発展させてきた実績がある。
同社は2025年4月に「空間ロボティクス研究センター」を設立し、人とロボットが協調する新しい社会の実現に向けた研究を本格化させた。今回、同研究センターの成果として、複雑な実空間を把握するコンピュータビジョン技術をベースに実用的なフィジカルAIを実現する空間World Model技術を開発した。
空間World Model技術の特長
開発された空間World Model技術の特長は以下の2点である。
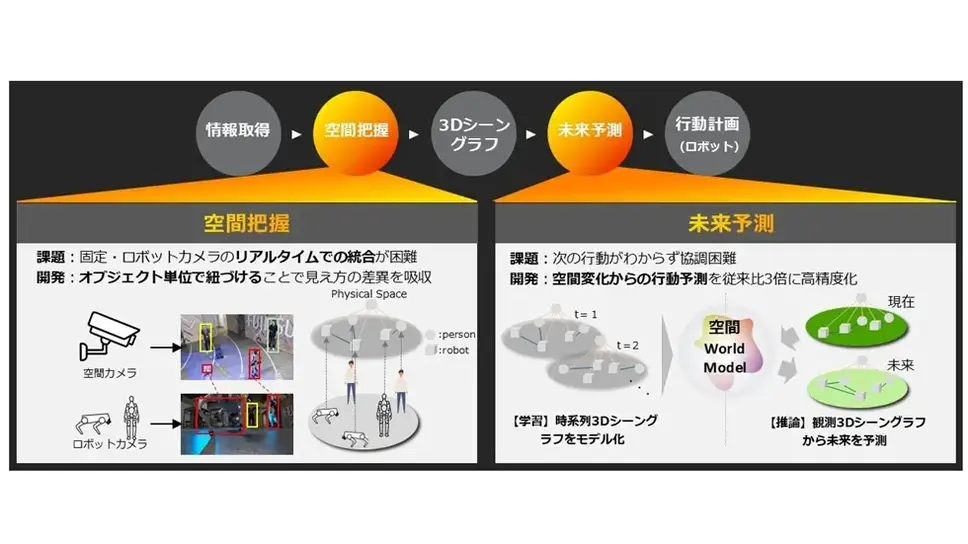
人・ロボット・モノの相互作用に着目した3Dシーングラフで空間World Modelを構築
一般環境では人やロボットが移動するなど、空間の状況も動的に変化する。空間全体を把握するために防犯カメラやロボットカメラを統合する技術が検討されてきたが、各カメラで捉えられる範囲や、固定型カメラと移動型カメラでの見た目の差異が大きく、動的に変化する空間をリアルタイムに把握することは困難だった。
そこで見た目の差異の影響を受けやすい画素単位での統合ではなく、人やロボットといった物体をベースに空間カメラとロボットカメラを統合して、視野や歪みなどの影響を抑えつつ空間全体を把握できる技術を開発した。これにより複雑に変化する実空間をリアルタイムに把握することが可能となる。
空間World Modelで人・ロボット・モノの相互作用をモデリングし、起こり得る行動を推定して未来の状態を予測
人やロボットが協調するためには、相手の行動だけでなく行動の背景にある意図を推定して未来の行動を予測することが重要となる。
ロボットの周囲の変化を予測して自身の行動を決めるWorld Model技術が盛んに研究されているが、目の前の環境しかモデル化できず、空間中の人やロボットの状況変化を捉えることができなかった。そこで空間における人、ロボット、モノの3Dシーングラフの時系列データを活用して、空間全体のWorld Modelを学習する方式を開発した。
人、ロボット、モノ間の多様な相互作用性から、複数の行動主体が起こす次の行動を推定することで、対象の空間における未来の状態を予測する。空間内を時系列に予測することで、自律ロボット間の衝突回避や複数ロボット間での最適な協調動作プランの生成などを実現できる。
技術実証と今後の展開
これらの技術により、学術的な公開ベンチマークデータ(JRDB-Social)において、他者の行動意図推定精度を従来の3倍向上(同社比)できることを確認した。
富士通は2026年度中(同社の決算期は3月末日)に、同社の本店で研究開発の主要拠点であるFujitsu Technology Parkなどを活用して技術実証を進めていく予定だ。
同技術は深刻化する労働力不足への対応や産業の生産性向上に向けて、人とロボットが協調する新しい社会の実現に貢献することが期待される。