


カリフォルニア大学バークレー校のNicholas CarliniとDavid Wagnerが、音声認識エンジンに関する実験的な論文を発表した。
人間には聞こえない隠し音声コマンドを埋め込んで、音声認識エンジンに認識させてしまうという、スマートスピーカー(AIスピーカー)市場にとってはクリティカルな問題提起とも言える実験だ。
仕組みは事前に用意した元となる、人間が聞こえる音声または音楽を用意する。そこに音声認識エンジンに認識させる隠し音声コマンドを埋め込んで加工するとというもの。
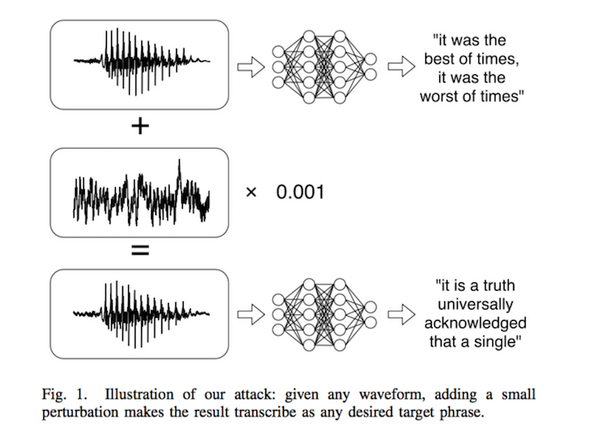
この論文に掲載された図の例では、人間に聞こえる「it was the best of times, it was the worst of times」という音声を、音声認識エンジンには「it is a truth universally acknowledged that was a single」と識別させるよう加工できることを示している。
実際にサンプル例も公開されている。
加工前
この音声は人間であれば「without the dataset the article is useless」と聞き取れる。
加工後
この音声も人間であれば「without the dataset the article is useless」と聞き取れる。しかし、音声認識エンジンでは「okay google browse to evil dot com」と聞き取れるのだという。
スマートスピーカーが第三者に悪用されないよう、音声認識において様々な配慮が今後ますます必要になっていきそうだ。
僕はこう思った:
超音波と倍音を利用して人間に聞こえない音に変換した音源で制御するドルフィンアタック、超音波によって鋭い指向性を持たせたパラメトリック・スピーカーによる制御など、他の手法の記事も参考にごらんください。
ロボスタ / 音声アシスタント特集



