

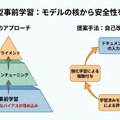
大規模言語モデル(LLM)の開発現場では、事前学習で獲得した膨大な知識を、ファインチューニングやアライメントと呼ばれる後工程で「安全」かつ「正確」に仕上げる手法が主流となっています。しかし、事前学習段階で深く刻み込まれた不正確な情報や危険な振る舞いのパターンは、後から完全に修正することが難しいという課題が指摘されてきました。
Meta AIの研究チームが発表した論文「Self-Improving Pretraining」は、この問題に正面から取り組む新しいアプローチを提案しています。事前学習の段階から強化学習(RL)を組み込み、品質・安全性・事実性を「最初から」織り込むことで、根本的に優れたモデルを育てる手法です。本記事では、この「自己改善型事前学習」の仕組みと成果を詳しく解説します。
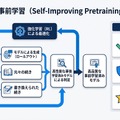
後工程の限界
現在のLLM開発では、まず大量のテキストデータで事前学習を行い、その後にタスク特化型のファインチューニングを施し、最後に人間のフィードバックを用いたアライメント(RLHF: Reinforcement Learning from Human Feedback)で安全性を高めるという、三段階のパイプラインが標準となっています。各段階で高価なデータセットを用意し、慎重な調整を重ねることで、実用レベルの品質を実現してきました。
しかし、この複雑なパイプラインにも限界があります。事前学習で学習されたパターンは、モデルの「核」となる振る舞いを形成するため、後工程でいくら調整しても完全には上書きできません。誤った情報や偏見、危険な出力傾向が事前学習時に深く埋め込まれてしまうと、それを後から取り除くことは極めて困難になります。
著者らは、この問題を解決するには「事前学習の段階から」安全性・事実性・品質を組み込む必要があると指摘しています。モデルの基礎を形成する最初の段階で望ましい振る舞いを学習させることが、根本的な解決策になるという考え方です。
提案手法の全体像
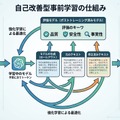
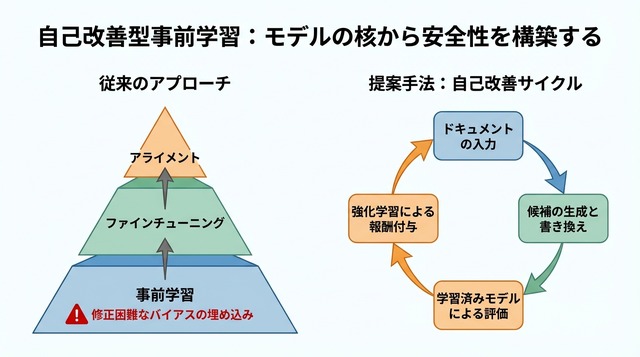
論文が提案する「Self-Improving Pretraining(自己改善型事前学習)」は、事前学習プロセスそのものに強化学習を統合した手法です。従来の事前学習では、テキストデータを順番に読み込みながら次のトークン(単語の断片)を予測する訓練を繰り返しますが、本手法ではこのプロセスに「改善のループ」を組み込んでいます。
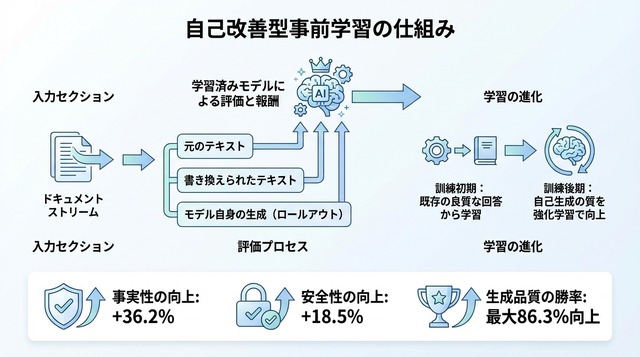
具体的には、ドキュメントをストリーミング形式で読み込みながら、各ステップで次に生成するK個のトークンを対象に強化学習を適用します。Kは事前に設定されたトークン数で、例えば次の10トークンや20トークンといった単位です。このK個のトークンについて、複数の候補を生成し、それらを評価して最も優れたものを選択する仕組みになっています。
この設計により、事前学習の段階から「より良い続き」を選択的に学習できるようになります。単に次のトークンを予測するだけでなく、品質・安全性・事実性の観点から望ましい生成パターンを強化していくことが可能になりました。
判定役モデル
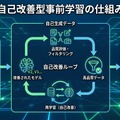
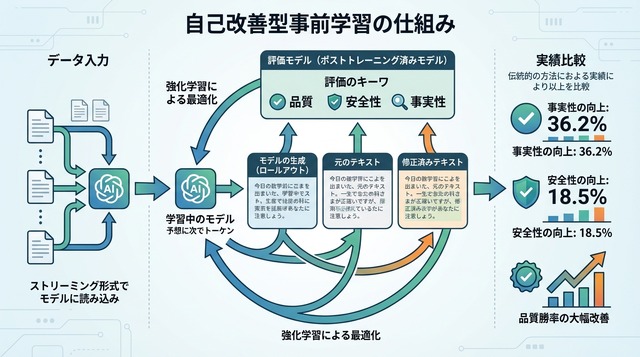
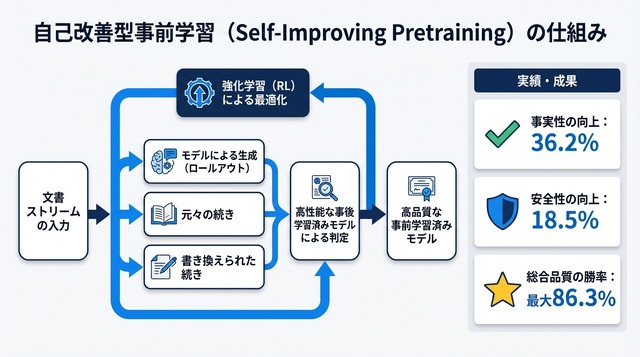
Self-Improving Pretrainingの中核を担うのが、「判定役」として機能する強力な事後学習モデル(post-trained model)です。このモデルは、すでにファインチューニングやアライメントを完了した高性能なLLMで、生成候補の品質を評価する「審判」の役割を果たします。
各学習ステップでは、3種類の候補が用意されます。第一に、訓練中のモデル自身が生成を続けた「ロールアウト」、第二に、元のデータセットに含まれる続きをそのまま使う「元のサフィックス」、第三に、人間またはAIが書き直した「書き換えサフィックス」です。これら3つの候補を、判定役モデルが品質・安全性・事実性の観点から評価します。
評価結果は強化学習の報酬信号として使われます。高い評価を受けた候補ほど、訓練中のモデルがそのような生成パターンを学習する確率が高まります。この仕組みにより、事前学習の段階から「望ましい出力」を選択的に強化できるようになっています。
学習の進め方
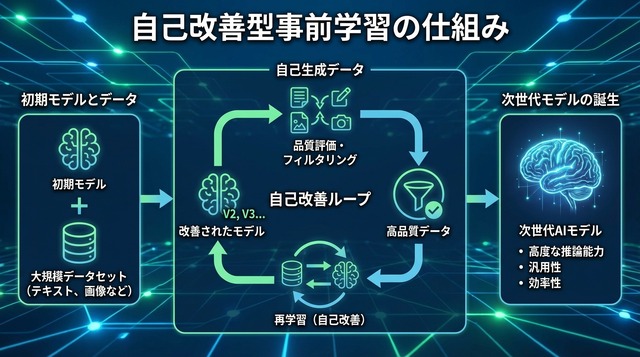
Self-Improving Pretrainingには、段階的な学習設計が組み込まれています。訓練の初期段階では、モデル自身の生成能力がまだ未熟なため、元のサフィックスや書き換えサフィックスといった「既存の良質な続き」に主に依存します。これにより、基本的な言語パターンと望ましい振る舞いの基礎を学習します。
訓練が進むにつれて、モデル自身が生成するロールアウトの品質が向上してきます。このタイミングで、強化学習は高品質なロールアウトに対してより大きな報酬を与えるようになります。つまり、モデルが自分自身で生成した優れた続きを評価し、それを強化していくという「自己改善」のサイクルが確立されます。
このカリキュラム的な設計の狙いは、Kトークン単位で逐次的に改善を積み重ねることにあります。事前学習の早い段階から望ましいパターンを学習させることで、不正確さや危険な振る舞いといった「悪い癖」がモデルの深層に刻み込まれることを防ぎます。
実験結果と数値
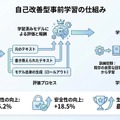
論文では、標準的な事前学習手法との詳細な比較実験が報告されています。事実性(factuality)の評価では、Self-Improving Pretrainingが36.2%の相対的改善を達成しました。これは、生成されたテキストに含まれる事実誤認や幻覚(hallucination)が大幅に減少したことを示しています。
安全性(safety)の面では、18.5%の相対的改善が確認されました。有害な内容や偏見を含む出力、倫理的に問題のある応答が減少し、より安全なモデルが実現されています。さらに注目すべきは、総合的な生成品質(overall quality)における勝率で、最大86.3%という大幅な改善を記録した点です。
これらの数値は、人間評価者または高性能な判定モデルによる比較評価に基づいています。事実性は検証可能な情報の正確さ、安全性は有害性や偏見の有無、総合品質は流暢さ・適切さ・有用性などを総合的に評価した指標です。いずれの指標でも、事前学習段階からの改善アプローチが効果的であることが実証されました。
意義と課題
本研究の最も重要な意義は、LLM開発における考え方の転換を示した点にあります。従来の「まず学習し、後から修正する」というアプローチから、「最初から望ましい振る舞いを織り込む」方向への移行を提案しています。これは、アライメントを事後的な「パッチ」として扱うのではなく、モデルの基礎構造に組み込むという発想の転換です。
一方で、いくつかの課題も存在します。第一に、判定役モデルへの依存性です。評価の質は判定役モデルの能力に大きく左右されるため、判定役自身に偏りや限界がある場合、それが訓練中のモデルにも引き継がれる可能性があります。
第二に、計算コストの問題です。各ステップで複数の候補を生成し、判定役モデルで評価するプロセスは、標準的な事前学習よりも計算資源を多く必要とします。大規模なモデルを訓練する際には、このコストが実用上の制約となる可能性があります。第三に、実運用での適用範囲です。論文では特定の規模とタスクでの実験結果が報告されていますが、さまざまなドメインやモデルサイズでの汎用性については、今後の検証が必要です。
それでも、事前学習段階からの品質向上という方向性は、今後のLLM開発に大きな影響を与える可能性があります。より安全で正確なAIシステムを、根本から構築するための重要な一歩と言えるでしょう。





