ロボットが目で見た情報を理解し、言葉の指示に従って動く「視覚・言語・行動(VLA)モデル」が注目されている。VLAモデルはロボット操作で高い汎化性能を示す一方、推論計算が重く実運用の障害になっている。本稿では arXiv:2602.00686v1(Yujie Wei氏ら)の「適応的な視覚トークンキャッシュ」による高速化と、速度と成功率を両立した点を概説する。
計算コストの壁
VLAモデルが実機ロボットで直面する最大の課題は、リアルタイム性に直結する推論の計算オーバーヘッドである。カメラから得られる視覚入力は、モデルが扱える「トークン」という単位表現に変換される。この変換と処理には大量の計算が必要で、フレームごとに繰り返されるため負荷が累積する。
ロボットアームが物体を掴む、あるいは道具を使うといった操作では、毎秒数十フレームの画像を処理しなければならない。VLAモデルは視覚・言語・行動を統合するため、各フレームで視覚エンコーダ、言語モデル、行動デコーダが連携して動作する。結果として推論レイテンシが増大し、リアルタイム制御の要求を満たせない状況が生じる。
この計算コストの壁を乗り越えなければ、VLAモデルの優れた汎化能力も実用化には至らない。高速化は単なる性能改善ではなく、実世界展開の前提条件となっている。
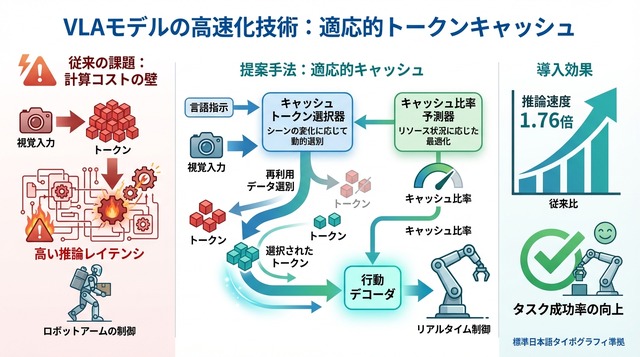
従来の高速化
既存の高速化手法は、ルールベースのトークンキャッシュやプルーニング(不要部分の削減)が主流であった。これらの手法は「静的・ヒューリスティック」な戦略に基づいており、事前に定めた規則に従って計算を省略する。例えば「前フレームと類似度が高ければ再計算しない」といった固定ルールが典型例である。
しかし、こうしたアプローチはタスクの目的から切り離されており、動的なシーン変化に適応できない。ロボットが物体を持ち上げる瞬間と、静止した状態では視覚情報の重要性が異なる。固定ルールでは、タスクの進行に応じて「どこを詳しく見るべきか」を判断できないのである。
さらに、ヒューリスティックな閾値設定は環境やタスクごとに調整が必要で、汎用性に欠ける。VLAモデルの強みである多様なタスクへの適応力を活かすには、加速戦略自体も学習可能であるべきだという課題が浮上した。
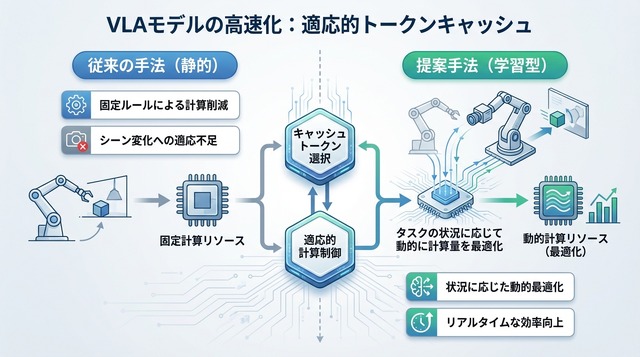
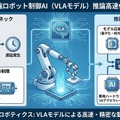
提案の全体像
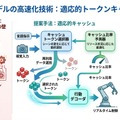
本研究は、推論加速を「学習可能な方策最適化問題」として再定義した。タスクに応じて計算配分を決める意思決定プロセスを、VLAモデル自体に統合する狙いである。これにより、モデルは「いつ、どの視覚情報を再計算し、どこを省略するか」をタスク目標に沿って学習する。
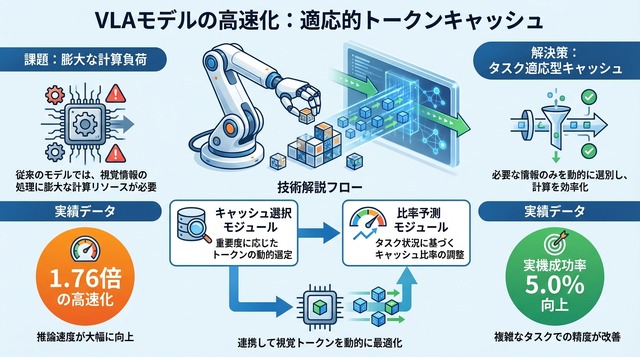
中核となるのが、視覚トークンの再利用(キャッシュ)を動的に制御する枠組みである。従来のVLAモデルは毎フレーム全トークンを再計算していたが、提案手法ではフレーム間で変化の少ない領域のトークンをキャッシュから再利用する。どのトークンをキャッシュするか、どれだけの比率で再利用するかは、タスクの状態に応じてリアルタイムに決定される。
この枠組みは、計算資源の配分を「強化学習的な方策」として扱う。ロボットが成功しやすい行動を学ぶのと同様に、推論を速くしつつ精度を保つ計算配分を学習するのである。タスク目標と加速戦略が一体化することで、汎用性と効率性の両立を目指す。
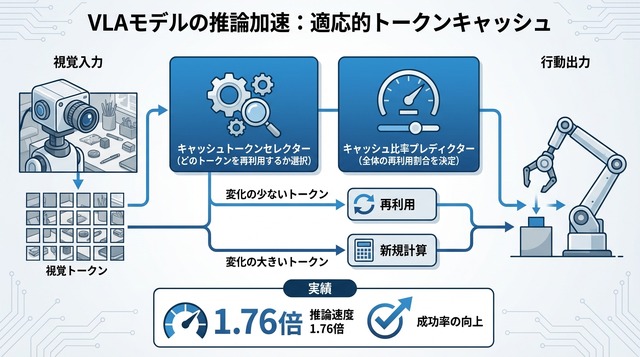
2つのモジュール
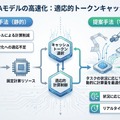
提案手法の実装では、2つの軽量な協調モジュールが導入されている。Cached Token Selector (キャッシュトークンセレクター)は、どのトークンを再利用するかを選択する。各トークンについて「前フレームの情報を使い回すか、新たに計算し直すか」を判断する役割である。
もう一方のCache Ratio Predictor (キャッシュ比率プレディクター)は、全体としてどれだけの比率でトークンを再利用するかを決定する。シーンの変化が少ない静的な状況では高い比率でキャッシュを使い、物体が動くなど変化が大きい場面では比率を下げて再計算を増やす。
この2つのモジュールは協調して動作する。Selectorが個別トークンの重要度を評価し、Predictorが全体の計算予算を調整することで、「タスク・状況依存」の適応的なキャッシュ戦略が実現される。シーンがあまり変わらない部分は再計算を省き、変化が大きい部分は確実に更新するという、人間の注意メカニズムに近い挙動が得られる。
両モジュールは軽量に設計されており、VLAモデル本体に追加する計算コストは最小限に抑えられている。推論全体を高速化する目的で、加速機構自体が重くなっては本末転倒だからである。
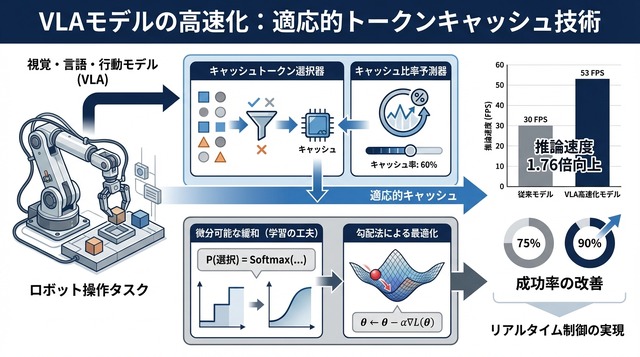
学習の工夫
SelectorやPredictorの判断は本質的に離散的である。「このトークンをキャッシュする/しない」という二値選択や、比率の段階的な決定は、微分不可能な操作になる。そのままでは勾配法による学習ができず、VLAモデル全体とのエンドツーエンド最適化が困難である。
著者らはこの課題に対し、「微分可能な緩和(differentiable relaxation)」を採用した。離散的な選択を確率的な重み付けに置き換え、期待値として扱うことで勾配を計算可能にする。具体的には、Gumbel-Softmaxなどの手法を用いて、訓練時には連続的な分布として扱いつつ、推論時には離散的な決定に戻す。
この工夫により、Selector・Predictor・VLAモデル本体を一括で最適化できるようになった。タスクの成功率を目的関数に含めることで、「速度と精度のトレードオフ」を学習プロセスに組み込める。モデルは、どの程度キャッシュを使えば成功率を維持しつつ高速化できるかを、データから自動的に学習する。
訓練データには、LIBEROやSIMPLERベンチマークの多様なロボット操作タスクが用いられた。この多様性が、提案手法の汎用性を支える基盤となっている。
実験結果
提案手法は、LIBEROベンチマークとSIMPLERベンチマーク、さらに実機ロボット評価で検証された。LIBEROは90種類のロボット操作タスクを含む大規模ベンチマークで、SIMPLERは実世界に近い複雑なシーンを扱う。いずれも、VLAモデルの汎化能力を測る標準的な評価環境である。
ウォールクロック推論時間(実際の経過時間)で、提案手法は1.76倍の高速化 を達成した。これは、従来の静的キャッシュ手法や固定比率のベースラインを大きく上回る。注目すべきは、速度向上と同時に精度も改善した点である。LIBERO平均成功率は75.0%から76.9%へ1.9ポイント改善 された。
実世界タスクでは、さらに顕著な効果が見られた。実機ロボットによる評価では、成功率が5.0ポイント向上 している。これは、提案手法がシミュレーション環境だけでなく、ノイズや不確実性の多い実環境でも有効であることを示す。動的な適応が、予期しない状況変化への対応力を高めた結果と考えられる。
既存のベースライン(静的キャッシュ、固定プルーニング、ルールベース手法)との比較でも、提案手法は全ての指標で優位性を示した。特に、タスクの種類や難易度が変わっても安定した性能を維持する点が評価されている。
今後の展望
本研究が示す「タスクを考慮した計算資源割り当て方策を学習する」方向性は、VLAモデルの実用化に重要な示唆を与える。実運用で求められるのは、レイテンシと成功率の両立である。提案手法は、この二律背反を学習可能な最適化問題として扱うことで、両者のバランスを自動調整できることを実証した。
動的環境への適応という観点でも、本手法の意義は大きい。工場の組立ラインや家庭内の支援ロボットなど、実世界の環境は常に変化する。固定的な加速戦略では対応しきれない状況で、学習ベースの適応的な計算配分が力を発揮する。
今後の論点としては、適用範囲の拡張が挙げられる。本研究はVLAモデルを対象としているが、同様の考え方は他のマルチモーダルモデル(視覚・言語モデル、動画理解モデルなど)にも応用可能である。また、キャッシュ以外の高速化手法(量子化、蒸留)との組み合わせも興味深い研究方向となる。
評価の拡張も重要である。より長時間のタスクや、複数ロボットの協調動作における効果の検証が求められる。加えて、学習コストやメモリ使用量といった実装上の詳細な分析も、実用化には不可欠であろう。VLAモデルが「速く賢く」動作する未来に向けて、本研究は重要な一歩を刻んでいる。