



2026年3月16日(現地時間)、GTC2026の基調講演にNVIDIAの創業者 兼 CEOのジェンスン・フアン氏が登壇し、AIの将来に向けた大きな変革を発表した。


最も注目すべきは、NVIDIAがGroqの技術を活用した推論向け製品を打ち出し、推論処理を分解する新しいシステム構成を示した点だ。従来のGPU中心の構成から、前処理(Prefill)をNVIDIA側、トークン生成(Decode)をGroqベースのチップが担うという役割分担へと踏み込んだ。これは、AIの主戦場がトレーニングから推論へと移行していることを象徴する動きと言える。

GB300 NVL72はBlackwell世代の延長にある現行プラットフォームであり、今回発表された「Vera Rubin」(ベラ ルービン)はその次世代にあたる。

CPUの強化とGroqベースの推論チップとの連携「AIシステム全体の再設計」
「NVIDIA GTC 2026」では、午前11時からジェンスン・フアンCEOが基調講演を行い、AIコンピューティングの新たな方向性を明確に打ち出した。講演では、GPU中心の構成からさらに一歩踏み出し、CPUの強化とGroqベースの推論チップとの連携を含めた「AIシステム全体の再設計」が示された。
ちなみに、NVIDIAはGroqを買収したわけではなく、約170億ドル規模のディールによりLPU技術のライセンスを取得、人材の獲得も行ない、実質的にその技術を自社のAIシステムにスマートに組み込んだ。
これまでNVIDIAは、主にGPUによる並列計算を軸にAI市場をリードしてきた。しかし、生成AIの普及によってAIの利用フェーズは大きく変わり始めている。いま重視されているのは「学習(トレーニング)」だけでなく、「推論(インファレンス)」だ。今回の基調講演でも、フアンCEOは推論需要の急拡大を強く意識した構成を示した。
実は世界的に報道関係者はこの動きを予想していて、基調講演ではどのような発表内容になるのかが注視されていた。
そもそも「LPU」とは何か
LPUは「Language Processing Unit」の略称で、Groqが展開する言語モデル向け推論処理に最適化されたプロセッサだ。GPUが幅広い用途に対応する汎用並列プロセッサであるのに対し、LPUは推論、とくに低遅延でのトークン生成を重視した設計思想を持つ。Groqは公式に、LPUについて静的スケジューリング、決定論的実行、高い電力効率を特徴として訴求している。
ただし、「GPUより優れている」という表現は正しくない。特定の推論ワークロード、特に高速・低遅延のトークン生成が重要な場面で優位性を打ち出している。Groq自身も、LPUの価値を主にリアルタイム推論や高速応答の文脈で説明している。

「Prefill」と「Decode」
生成AIの推論処理は、大きく2つのフェーズに分けられる。1つは入力をもとに文脈を理解するPrefill、もう1つは実際に文章を生成するDecodeだ。今回NVIDIAが示したのは、このうちPrefillをVera Rubin側で処理し、DecodeをGroqベースのチップで担うという考え方である。
このDecodeフェーズでは、1トークンずつ順次出力していくため、応答速度や遅延の安定性が非常に重要になる。チャットAIやエージェント型AIでは、ここでの体感速度がサービス品質を大きく左右する。Groqベースの推論チップは、こうした領域での性能向上を狙ったものとして位置づけられるようだ。
GPU中心から「システム全体の再定義」へ、CPUも強化
フアンCEOは講演の中で、AIはもはや単一のチップで完結するものではなく、システム全体として設計されるべき段階に入ったと強調した。従来のAIインフラではGPUが主役で、CPUは補助的な存在と見られがちだった。しかし、AIエージェントや大規模言語モデルの普及に伴い、データ処理やオーケストレーション、メモリ管理といった役割の重要性が増している。

NVIDIAはGrace CPUを2022年に発表し、その後CPU戦略を本格化させてきた。現在のGrace CPU Superchipは、Arm Neoverse V2ベースの144コア構成、最大1TB/sのメモリ帯域などを特徴としている。今回のGTCでは、CPUがAIシステムの“司令塔”としてさらに存在感を増していることが明確になった。
CPUの役割としては
AIエージェントの実行制御
大規模データの前処理
メモリおよびKVキャッシュ管理
分散システムのスケジューリング
といった整理で問題ないだろう。これらはNVIDIAが今回強調したAIシステム全体の最適化という文脈にも整合している。
Groq連携が示した「推論最適化」
今回の発表でもう1つ注目されたのが、推論処理を用途ごとに分解して最適化する発想だ。NVIDIAは、推論をPrefillとDecodeに分け、それぞれに適したハードウェアを割り当てる構成を前面に出した。前処理はNVIDIAのVera Rubin系、トークン生成はGroqベースのチップという役割分担は、推論時代の分業型アーキテクチャを象徴している。

これは、「GPU一強」からの転換というより、GPUを中心にしつつ、用途ごとに最適なプロセッサを組み合わせる方向への進化と見るほうが正確だろう。すなわち、
CPU(制御・データ処理)
GPU(大規模並列計算)
LPU/Groq系チップ(低遅延推論)
という分業型構成だ。
推論時代の到来と巨大需要
生成AIの普及により、ユーザーがAIを使うたびに発生する推論処理は、今後の市場の中核になると見られている。フアンCEOは今回、AIハードウェア需要が2027年までに少なくとも1兆ドル規模に達するとの見通しを示した。これは以前の5000億ドル予測から大きく引き上げられた数字であり、推論需要の急増を織り込んだものと見られる。
AIコンピューティング全体の再設計
GTC2026でNVIDIAが提示したのは、GPU単体の進化というより、AIコンピューティング全体の再設計だった。
CPUの役割拡大
GPUを中核にしつつGroqベース推論チップを組み合わせる構成
推論を重視した分業型アーキテクチャへの移行
こうした変化は、AIが次の段階へ進んだことを示している。AIはもはや単なるソフトウェアではなく、複数のプロセッサが連携する巨大なシステムとして、社会インフラへと組み込まれようとしている。



今回NVIDIAが示したのは、新しいチップではなく、AIの“作り方そのもの”の転換である。現行のGB300 NVL72がBlackwell世代の完成形であるのに対し、Vera Rubinはその次の世代として位置づけられる。そして、この変化の本質は単なる性能向上ではない。CPU、GPU、LPUを組み合わせた分業型アーキテクチャによって、AIのコスト構造そのものが再定義されようとしている。
更に詳しく(NVIDIAの事前ブリーフィングより)
基調講演に先立ち、同社のVP、イアン・バック氏らによる報道関係者向けブリーフィングが開かれた。
NVIDIAのバック氏は「AIはいよいよ次の時代に入る」と説明した。そこで強調されたのは、推論、エージェント、データ、モデルといった複数の軸でAIがスケールしていくという考え方だ。とりわけ、AIが人間と対話するだけでなく、AI同士が連携しながら処理を進める「AIマルチエージェント」型の利用が広がれば、低遅延かつ広大なコンテキストを扱える推論基盤への需要は、これまで以上に高まると見られる。
今回の基調講演と同社による発表は、この方向性を強く意識したものとなっている。
NVIDIAは今回、AIインフラを単なるチップの延長ではなく、チップ、システム、ネットワーク、ソフトウェア、モデルまでを含めて設計する統合基盤として位置づけた。ジェンスン・フアンCEOが繰り返し用いた「AIファクトリー」という言葉も、その象徴だ。単体の半導体性能ではなく、データセンター全体をどう設計し、推論効率に結びつけるかが、今後の競争軸になるという考え方である。
その延長線上にある次のステップとして打ち出されたのが、「Vera Rubin」プラットフォームだ。これは、NVIDIA Vera CPU、Rubin GPU、NVLink 6、BlueField-4 DPU、ConnectX-9 SuperNICなどで構成される次世代AI基盤であり、学習から推論、エージェント処理までを一体で支える設計となっている。
ここで重要なのは、Groqとの関係だ。NVIDIAはGroqを買収したわけではなく、2025年末に同社技術に関するライセンス契約を締結し、その推論技術を自社のAIシステムに組み込んだ。今回のVera Rubinでは、Groqベースの推論アクセラレータが正式な構成要素として統合されている。
今回の発表の中核となるのが、推論処理を2つのフェーズに分解するアーキテクチャである。入力を理解し文脈を構築する「Prefill」をVera Rubin側が担い、応答を1トークンずつ生成する「Decode」をGroqベースの推論チップが担う。この分業構造により、処理特性に応じて最適なハードウェアを割り当てることが可能になる。
LPUは、ロボットの「動き(ダイナミクス)」をリアルに計算・制御するためのNVIDIAの中核技術群「ダイナモ(Dynamo)」を通じて制御できるようになる見込みだ。ほとんどの作業はGPUが担当するが、LPUが得意とする「Decode」部分ではGroqベースの推論チップが活躍するだろう。
Decodeフェーズは、低遅延かつ安定した応答速度が求められる領域であり、チャットAIやエージェント型AIにおいて体感品質を大きく左右する。GroqのLPUは、この低遅延推論に特化した設計を持つプロセッサであり、今回の構成ではその強みが最大限に活かされる形となっている。
Vera Rubin NVL72は、72基のRubin GPUと36基のVera CPUを中心に構成される高密度なAIシステムだ。これに加え、DPUやSuperNICなどのコンポーネントが統合され、データセンター全体での効率的な処理を実現する。単にチップを接続するのではなく、システム全体として最適化された設計である点が特徴だ。
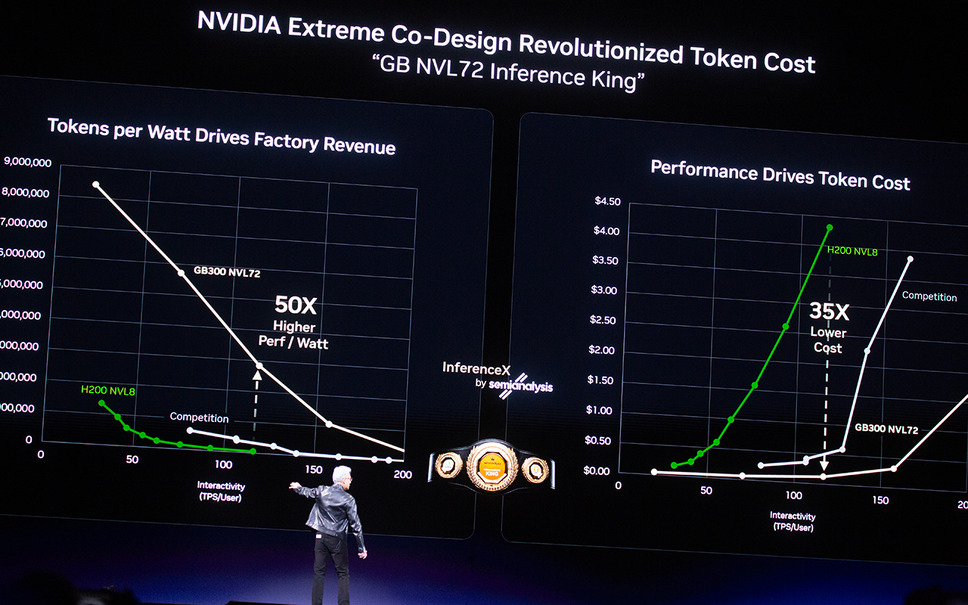
性能面では、前世代と比較して推論スループットあたりの電力効率が大幅に向上し、トークンあたりのコストも大きく削減されるとされている。さらに、Mixture of Experts(MoE)モデルの学習においても、より少ないGPU数で同等の成果を目指せる設計となっている。
前述のようにGroqベースの推論アクセラレータとして投入されるのが「Groq 3 LPX」だ。これは1ラックあたり最大256基のLPUを搭載し、大容量のオンチップメモリと極めて高い帯域幅を備えることで、低遅延かつ大規模コンテキストに対応する推論処理に最適化されている。
このGroq 3 LPXは、Vera Rubinと組み合わせることで、推論スループットあたりの電力効率を大幅に向上させるとともに、AIサービス全体の収益性改善にも寄与する設計となっている。重要なのは、GPUを置き換えるのではなく、GPUと役割分担することでシステム全体の性能を引き上げるという発想だ。
すなわち、CPUが制御とデータ処理を担い、GPUが大規模並列計算を担い、LPUが低遅延推論を担うという、分業型アーキテクチャになる。
さらに今回の発表では、CPUの重要性も改めて強調された。AIエージェントは単なる推論処理にとどまらず、データベースアクセス、コード実行、外部ツール連携といった複雑な処理を伴う。こうした処理はCPUが担う領域であり、高速なオーケストレーション能力が不可欠となる。
NVIDIAは、この役割を担うCPUとしてVeraを位置づけ、多数コアと高いシングルスレッド性能、さらに電力効率を兼ね備えた設計を打ち出している。AI時代のCPUは単なる補助ではなく、システム全体を制御する中核的存在へと再定義されつつある。
また、AI市場そのものも大きな転換点にある。AIの利用が広がるにつれ、ユーザーがAIを使うたびに発生する推論処理が、今後の市場の中心になると見られている。NVIDIAは、AIハードウェア市場が数年以内に1兆ドル規模へと拡大する可能性を示しており、その原動力は推論需要であると位置づけている。
こうした視点から見ると、今回の発表は単なる新製品の投入ではない。CPU、GPU、そしてLPUを組み合わせた分業型アーキテクチャによって、AIインフラそのものの設計思想を更新する提案だと言える。
AIはもはや単一のチップで完結するものではない。複数のプロセッサが役割を分担しながら連携する「システム」として進化している。その流れを最も明確に示したのが、今回のGTC2026の基調講演だった。