


d.a.t.株式会社は、Web上に掲載されているコンテンツをAIが自動で解析し、無断で複製や転載されていると判断した場合は、削除申請までをサポートするサービスを開始した。
このAIによるコンテンツ著作権侵害抑止サービスの名称は「RighTect」(ライテクト)。同社は「RighTect」を通じて、コンテンツ権利侵害対策強化の一助となることを目指すとしている。

「RighTect」が生まれた背景とコンテンツホルダーの課題
コンテンツ制作者やクリエイターなどコンテンツホルダーにとって、作品がインターネット上に複製されたり、無断転載など著作権侵害とみられるケースが増加し、深刻化が更に進むとの予測がある。また、個人のブログやTwitterなどへの投稿、まとめサイト、海賊版サイトなども含めると、その範囲は広大になる。自社コンテンツが不正に複製・転載されていた場合であっても、それらを発見し、ひとつずつ削除申請を行うのは膨大な時間と手間、コストがかかり、対応には限界があった。また、一時的に権利侵害に対応したとしても、次から次へと新たな転載コンテンツが生まれ、継続的な対応を行うのは現実的ではないという見方もあった。
こうした課題を重く捉え、AIがそれらの判断や作業を支援するサービスが誕生した。
「RighTect」のアプローチ
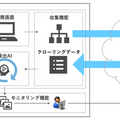
「RighTect」は、Web上から自動収集した写真画像、漫画画像、動画、記事テキストなど、掲載されているコンテンツとオリジナルと思われるコンテンツデータを独自の識別AIを用いてマッチングする。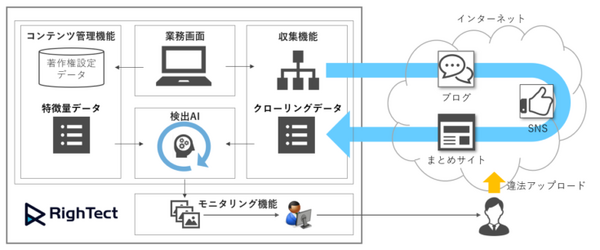
元画像を加工したり一部を切り取った画像であったり、元画像をスマートフォンで撮影した画像であっても、同一性を判定することが可能だとしている。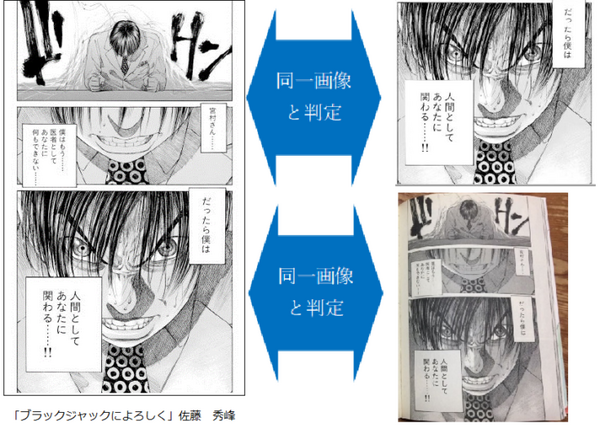
高い精度で不正に転載されているコンテンツをAIが自動で判別することで、著作権の侵害抑止に効果がある。同社が実施した実証実験では、オリジナルの写真画像・漫画画像コンテンツに対し、それらを加工した画像で同一性を判定させた結果、95%以上の精度で一致を検出したという。
コンテンツの事前登録
対象のコンテンツを画面上から事前登録
クローリング設定・収集
検索サイトにおける検索結果、特定サイトのURL等条件を指定してコンテンツをクローリング、目的のコンテンツを「RighTect」が自動収集
特徴量抽出・インデックス化
データの特徴量を抽出し、特徴量データとしてコンテンツをインデックス化し保存
AIによるマッチング処理
オリジナルコンテンツの特徴量と収集コンテンツの特徴量をN:Nで高速マッチング処理し、類似度を判定するAIを活用して類似度をスコア化
結果出力
類似度判定の結果、一定のスコア以上のコンテンツとソース(URL)をモニタリング対象案件として出力
d.a.t.株式会社
