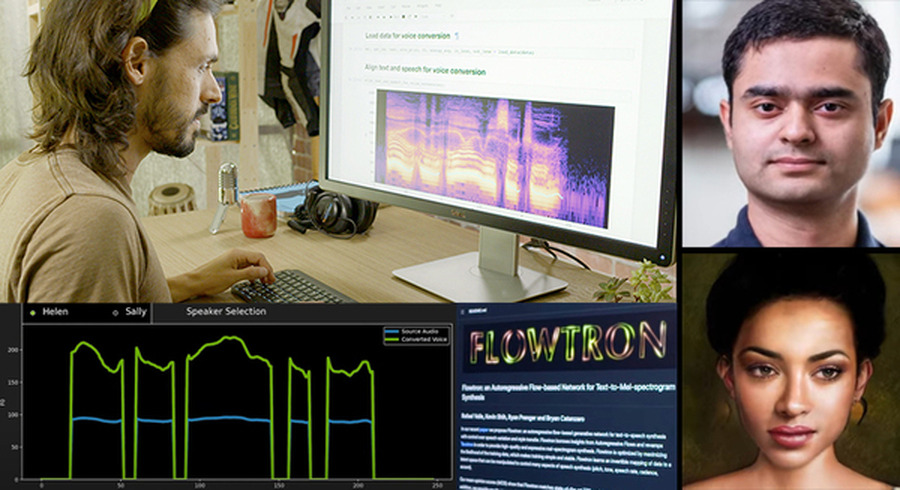




NVIDIAは31日、音声処理における世界最大規模の国際学会「INTERSPEECH 2021」カンファレンスへ参加することを発表した。それに伴い、自然言語処理の最新技術について、アジア圏の報道関係者に向けたプレスブリーフィングを開催した。
進化する自然言語AI
自動音声の電話、駅や公共施設でのアナウンス、GPSナビなど、合成音声システムによる発話は私達の生活に今では溶け込んでいる。その一方で以前からの単調な発話は、アクセントやイントネーションなどが不自然で、「コンピュータっぽい」と揶揄されたり、私達が使っている日常的な自然会話とはまだまだ大きな隔たりを感じさせるケースも少なくない。
AIがそれを一変しようとしている。既にスマホやスマートスピーカーの音声アシスタントなどの「会話AI」は洗練された話し方へと進化してきていて、人間に近い歌声までも披露するようになってきている。
NVIDIAは会話AIの幅はどんどんと広がっていて、ユースケースの例として「ビデオ会議でのライブ字幕」(Live captioning in video conferencing)、「医療関連の書類などの翻訳」(Medical transcription)、「チャットボットへの音声入力」(Chatbot with speech interface)、「音声を使った小売店のアシスタント」(Voice user interface for RETAIL ASSISTANT)などを紹介した。
そして、NVIDIAの研究チームは更に開発が必要だと感じている。
「AIで合成された音声と、日常的な会話やメディアから聞こえてくる自然な音声の間にはまだ隔たりがあります。人間の話し方には複雑なリズムや抑揚に加えて独特の声色があり、AI が模倣するのは困難だからです。ただ、この隔たりが急速に解消しつつあります。NVIDIA の研究者たちは、人工的な音声ではなく、人間の声が持つ豊かな表現力を取り込んだ、高品質で制御可能な音声合成用のモデルとツールの作成を進めています」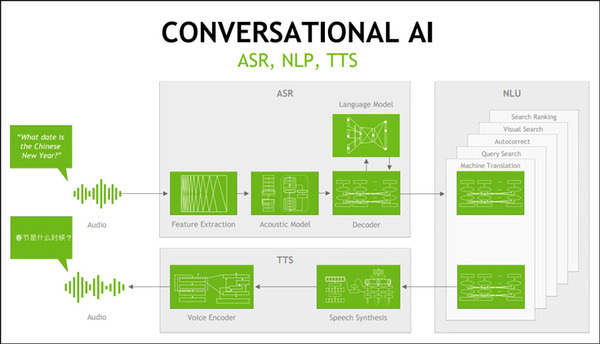
会話AI のユースケース
NVIDIAはこれらの技術をどのようなユースケースで利用できると考えているのだろうか。
「例えば、最近流行っているオンラインゲームストリーミングの動画の中で、リアルタイムでバックグラウンドのノイズを除去したり、音声を他の言語や他の地域のアクセントに変更して、自然な発音でアウトプットすることができます」と語る。報道関係者とのやりとりの中でも、今まで多くの英語の発音は、米国での会話データが機械学習に使われているなどの理由によって、米国英語のバイアスがかかっていたが、今後はそれを英国英語でアウトプットするなどの切替も考慮できるようになっていくことを示した。これは一例に過ぎないが、発音やアクセント、抑揚、感情表現などにおいて、より自然な発話が実現できることを示唆している。
ビデオゲーム制作の際、ゲーム中の音声をたくさんの言語で作ることはこれまで多額の費用がかかるものだった。今後はこれらの技術を使うことで費用を抑えて開発できるだろう。また、複数の言語だけではなくて、例えば、声優の収録がすでに終了した後に、シナリオや内容に変更が発生した場合、今までは音声を再収録する必要があったが、今後は音声合成を使って変更的にセリフを変更して作成することが容易になると考えている、とした。
ブリーフィングの質疑応答では、ジャーナリストから「これらの技術を使えば、ロボットも感情的にお話できるようになる?」という質問に対してCatanzaro氏は「まさにその通りです。ロボットの話し方がモノトーンではなく抑揚のついた、より自然なものになることによって、これからのロボットとのインタラクションは飛躍的により快適なものになるでしょう」と答えた。
「I am AI」のナレーションは音声合成
合成音声の応用例として、2017年のGTCの基調講演で公開された「I AM AI」の動画を覚えているだろうか。最近まで、このビデオシリーズのナレーションは人間が担当していたが、現在ではあの動画に使用されている女性の声は音声合成技術を使って生成されたものとなっているという。「自動生成による音声だと気づかなかった人もいるのではないでしょうか。人間のような抑揚や感表現が含まれていることが特徴で、その背景にはFLOWTRONという技術が使われていました。NVIDIAは研究だけでなく、SDKやモジュール、モデルやデータセットの提供もしています」と語った。
■ All the Feels: NVIDIA Shares Expressive Speech Synthesis Research at Interspeech
最近の数年でこの状況は大きく変化しているという。NVIDIAのTTS(Text-to-Speech:文字音声変換) の研究チームは「RAD-TTS」など制御可能な音声合成モデルを開発し、このモデルはSIGGRAPHリアルタイム ライブ コンテストで優勝したデモでも使用されたという。「RAD-TTS」では、個人の音声で Text-to-Speech モデルをトレーニングすることで、任意のテキストを話し手の音声に変換できる。
■I AM AI: Digital Avatar Made Easy SIGGRAPH Real-Time Live Demo
また、もうひとつの機能である音声変換を利用すると、ある話し手の言葉や歌声を、別の話し手の声にすることができる。人間の声を楽器として利用するアイデアからヒントを得た RAD-TTSのインターフェイスでは、合成された音声のピッチ、長さ、強さに対して、フレームレベルの詳細な調整や制御が可能となっている。
「表現力の豊かな音声合成は、対話型 AI に関する NVIDIA Research の研究の ひとつの要素に過ぎません。この分野には他にも、自然言語処理、自動音声認識、キーワード検出、オーディオ エンハンスメントなど、さまざまな要素が含まれています。この最先端の研究成果の一部は、NVIDIA GPU で効率的に実行できるよう最適化されており、NVIDIA「NeMo ツールキット」を通じて利用できるオープン ソースとして作成されています。このツールキットは、コンテナーやその他のソフトウェアを提供する NGC ハブから利用できます」としている。
■ Reinventing Graphics with AI | I AM AI
参考:AIによるグラフィックスの再発明
また、「テキストノーマライゼーション」と呼ばれる音声入力のデータセットを統一する技術も紹介した。例えば、音声入力で「ひゃくどる」と言った際、「100ドル」「$100」「百ドル」と、いくつも入力候補が出てしまうものを統一する技術だ。細かい話しだが、人による作業ではこれらは配慮しておこなわれているのが通常だ。
NVIDIA NeMoとは
「NVIDIA NeMo」は、GPUを使った機械学習等による高精度な対話型AIを実現するオープンソースのPythonツールキット。NVIDIAのブログによれば、研究者や開発者、クリエイターは、独自のアプリケーション向けに音声モデルを試用したり、微調整を行うことで、スムーズに開発を開始できる、としている。
また、研究者は、使いやすいAPIとNeMoで事前学習させたモデルを使って、Text-to-Speech、自然言語処理、リアルタイムの自動音声認識用のモデルを開発し、カスタマイズできる。いくつかのモデルは、NVIDIA DGX システムで何万時間分もの音声データを使用してトレーニングされたもの。開発者は、NVIDIA Tensorコア GPUの混合精度コンピューティングを使用してトレーニングを高速化することで、ユースケースに合わせてモデルを調整することが可能となっている。
NVIDIA NeMo では、Mozilla Common Voiceで学習したモデルをNGCを通じて提供している。Mozilla Common Voiceは、約14,000時間に上る、クラウドで収集された76言語の音声データによるデータセット。このプロジェクト自体は、音声データセットによって誰でも音声技術を利用できるようにすることを目的としたものだ。
「INTERSPEECH 2021」で紹介する技術
「INTERSPEECH 2021」は、音声技術の画期的な研究を紹介するカンファレンス。カンファレンスでは、NVIDIA Research が対話型 AIモデルのアーキテクチャや、開発者向け音声データセットについて等、6つのリリースペーパーに沿って発表がおこなわれる。いずれも既に発表されている技術に関するものだが、これらの技術が自然言語技術の最先端の一端となっている(日程は現地時間)。
Scene-Agnostic Multi-Microphone Speech Dereverberation (場所に依存しない複数マイクによる音声の残響抑圧) ニューラルネットワークでノイズを除去 — 8月31日(火)
SPGISpeech: 5,000 Hours of Transcribed Financial Audio for Fully Formatted End-to-End Speech Recognition(完全にフォーマット化されたエンドツーエンドの音声認識を実現する、5,000時間分の金融関連の音声の書き起こし — 9月1日 (水)
Hi-Fi Multi-Speaker English TTS Dataset (高品質の複数の話者による英語の TTS データセット) — 9月1日 (水)
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction (明示的に音の高さと長さを予測する音声合成のための、非自己回帰深度分離畳み込みモデル) — 9月2日 (木)
Compressing 1D Time-Channel Separable Convolutions Using Sparse Random Ternary Matrices (スパース ランダム 3 元行列を用いた、1 次元時間チャネル分離畳み込みの圧縮) — 9月3日 (金)
NeMo Inverse Text Normalization: From Development to Production (NeMo の逆テキスト正規化: 開発から運用へ) — 9月3日 (金)
NVIDIAは「INTERSPEECH では、1,000人を超える研究者が集まり、音声技術の画期的な研究を紹介します。今週のカンファレンスでは、NVIDIA Research が対話型 AI モデルのアーキテクチャや、完全にフォーマットされた開発者向け音声データセットについて発表します。ぜひご覧ください」と呼びかけた。



