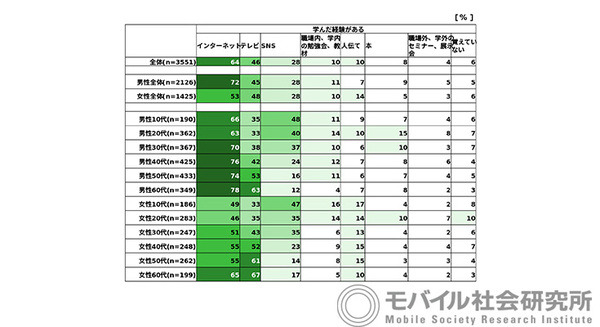
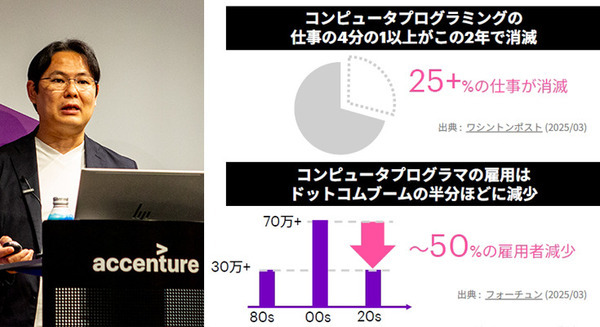
Open AIが昨年11月に発表した「ChatGPT」や、その高性能な大規模言語処理モデル「GPT-3」、最新版「GPT-4」が話題だ。「ChatGPT」は、ジェネレーティブAIを対話型AIに活用したチャットボットで、従来のチャットボットや音声アシスタントのように、ユーザーからの質問に答えるだけでなく、小説を書いたり、小説や記事の要約(サマリー)を書いたり、それらを指定した文字数内にまとめる、それを翻訳するなど、多岐に渡る才能を披露し、世間を驚かせている。
その「ChatGPT」と同様の大規模言語処理モデルを開発している日本の企業がある。株式会社オルツだ。2022年6月にシリーズDラウンドで35億円の資金調達を実施し、累計調達額は62億円に及ぶ。
オルツの高精度なチャットボット「LHTM-2」
オルツの大規模言語処理モデルの名称は「LHTM-2」(ラートム・ツー)で、「GPT-3」と同水準のパラメータ数で構成、機械翻訳や自動要約、テキスト生成、対話など、様々な用途に利用することができる。
また、高品質音声合成「AITalk」を開発・提供する株式会社エーアイとの業務連携を発表。この連携では、オルツの「LHTM-2」やChatGPTで知られる大規模言語処理モデルの対話AIをエーアイ製品に活用することを目的に、法人が利用可能な「ChatGPT」サービス構築を目指すとしている。
下の画像では文字が小さいので見づらいが「コーヒーの新商品ではどのポイントを抑えるべきか?」「フレーバーに拘った新商品のコーヒーの名前を3つ提案して」「マンゴーシナモンコーヒーの商品説明の記事を200文字くらいで作成して」という問いに「LHTM-2」が自然言語で回答している。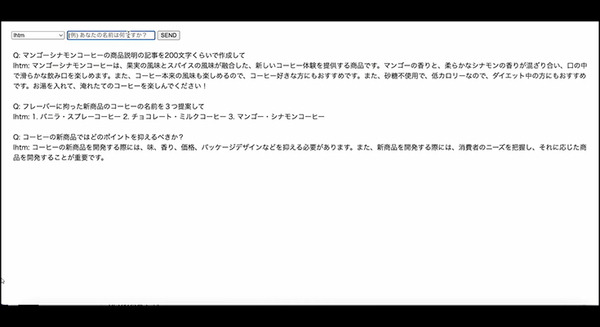
下の画像は、オルツの主力サービスである「AI GIJIROKU」について「LHTM-2」に質問した例。「サービス内容について教えて」「AI GIJIROKUの便利な使い方を教えて」「精度を上げ方は?」「使い方を説明した動画を見せて」「ありがとう」と入力している。
■動画 大規模言語処理モデル「LHTM-2」活用例 | alt Inc.
日本発の大規模言語処理モデルを開発しているオルツは、話題の「ChatGPT」をどう捉えているのか?
「LHTM-2」は「ChatGPT」とどのような差異があるのか、「ChatGPT」の登場によって今後はどのような社会変化が予想されるのか。「LHTM-2」開発責任者のオルツ、CTOの西川氏に話を聞いた。
大規模言語処理モデル「LHTM-2」とは
2023年2月14日に発表したリリースによれば、下記の点で従来の対話型AIの2つの課題を克服しているとしている。
【課題1:学習される前のことに関する知識をモデルが持たないという点】
「LHTM-2」ではリアルタイムに個人のライフログの入力を行うことによって、モデルが逐次進化し、日々の社会の変化に対応することが可能となった。「LHTM-2」はリアルタイムな学習を前提とした設計となっている。
「ライフログ」とは会議やレポートなどでの個人の発言等をログデータとして取り込む機能で、パーソナライズのひとつとして個性や個人の意見を自動的に取り込むことも可能となっている。
【課題2:モデルが事実とは異なる記述を出力するという点】
同社のパーソナライズ技術に基づき、出力の事実性を重視するよう言語モデルにカスタマイズを施すことにより、言語モデルが事実に基づく出力を行うことが可能となった。「LHTM-2」は、事実性に敏感なモデルとなっている。
「ChatGPT」は大量のテキストデータを学習することにより、前後関係が自然な会話が実現できるが、オルツの「LHTM-2」モデルは個性化、事実に基づく回答を目的としている「事実性の担保」という点で大きく異なる、としている。
オルツに聞く、大規模言語モデル「GPT-3」「ChatGPT」と、自社製「LHTM-2」の違いとは
編集部
オルツ社からは「ChatGPT」をどのようにみていますか?
西川氏
私達の業界では、大規模言語モデルとして「GPT」シリーズが開発されてきたことは周知のことでしたが、それをチャットボットとしてチューニングして、対話に特化した「ChatGPT」として発表したことは、マーケティング的に非常にインパクトがあったと感じています。OpenAI社は、これまでGPTの技術開発を積み重ねてきた成果として高性能な「GPT-3」に昇華させ、その機能を使いやすく「ChatGPT」としてラッピングし、世界を驚かせたことで、対話型AIは注目を一気に集めた、と感じています
編集部
代表的な音声対話AIとしては「Siri」や「Googleアシスタント」「Alexa」などが身近にありますが、それらと比較して「ChatGPT」はなぜ、これほどまで性能面での進化を遂げたのでしょうか。
西川氏
本質的に重要なポイントは、言語モデル、すなわち自然なテキストを生成する能力が、一定値を超えたという見方が妥当だと感じています。「GPT-3」は約1,750億のパラメータで構成されていると言われていますが、大規模なパラメータに対して大規模なデータを投入した結果として、自然なテキストを生成する能力が格段に進化したと言えるでしょう。Transformerと呼ばれるモジュールや深層学習モデルを大量に重ねまくって、ビッグデータを投入し、大規模な計算資源で処理すれば、これほどの自然言語処理能力を備えた対話型AIができる、ということがわかった、ということだと思います。
編集部
御社オルツの視点で見ると、「ChatGPT」は競合する技術ですか。それとも連携すべき技術でしょうか。
西川氏
チャットボットという分野でみれば競合する技術に見えると思いますが、事業的な観点で見れば、OpenAI社のアプローチと、当社が目指す「LHTM-2」のアプローチは全く異なっています。「ChatGPT」は言うなれば、全世界に対して、とにかくあらゆる質問に自然に回答できる大規模言語モデルを目指しているのに対して、「LHTM-2」はお客様向けにカスタマイズし、ハルシネーション(編集部注釈:もっともらしく言うウソや間違い)のないように、正しく役立つ情報だけを提供しようというアプローチです。そうでなければ多くのビジネス現場では有効に活用できないと考えているからで、そこには「ChatGPT」とは大きな違いがあります。
ただし、雑談AIのように幅広くそれらしい回答を返すチャットボットをクライアントや連携パートナーか望む場合は、「GPT-3」や「GPT-4」や、「ChatGPT」とAPI連携したシステムを構築することは可能です。
編集部
インターネットや論文などから膨大な情報を得るには、どうしてもウソや間違った情報も含まれてしまいます。一方、正確な回答だけを返そうと思えば、人が手間暇を掛けてルールベースでQ&Aのようなものを作らないといけない、それでは回答できる範囲もごく狭い範囲に限られてしまう、というのがこれまでの常識でした。「LHTM-2」が目指すところにはそのような矛盾が壁にはならないのでしょうか。
西川氏
当社は、2023年2月にベクトルグループとの業務提携を発表しています。ベクトルグループのように、既にオウンドメディアで大量の記事を作成していたり、プレスリリース等の報道向け資料や各種広告クリエイティブに関する文章を多く作成している企業においては、それらの情報をそのままビッグデータとしてAIに学習させることで、事実性を担保し、常に最新情報にアップデートした大規模言語モデルを構築することができます。
そこにはOpenAIの「GPT-3」を活用するとともに、「GPT-3」等と同水準のパラメータ数で構成されている「LHTM-2」を活用しています。自然なテキストが生成可能で、かつ「カスタマイズ」を前提とした柔軟な設計であることから、事実に基づく出力を内部的に誘導することができるので、ハルシネーションを防ぐことができるのです。
「LHTM-2」と「ChatGPT」の違い
「ChatGPT」は、ユーザーから得た情報も知識として蓄積してしまうことが問題点としてあげられている。すなわち、他の人が入力した情報が、別の人の対話に使われる可能性があるということ。プライバシーに関わる情報も時として返答してしまう恐れもある。「LHTM-2」では、この問題を深刻に捉え、個人が入力した情報が運営者に抜けてしまうことがないように開発し、ビジネスで使用しても信頼できるシステムとして構成、それも総じて「カスタマイズ」をおこなっている、と語った(「LHTM-2」はビジネス向けに情報保護機構があり、専門用語や企業独自のFAQなどを追加するカスタマイズ性が高い)。
西川氏は「GPT-3」やチャットボットに特化した「ChatGPT」の性能を高く評価しながらも、ビジネスに活用するためには「ChatGPT」は設計上、カスタマイズ性や情報保護の面で難しく、「LHTM-2」の特長としているカスタマイズ性の高さや情報保護の徹底は欠かせない、と続けた。また、「GPT-3」を凌駕するカタチで登場した最新の「GPT-4」は最新の情報を含めてパラメータもデータも格段に増えて、性能は大きく進化している。しかし、「GPT-3」より最新の情報のため事実性は向上しているとは言え、事実性は担保されてはいない(ハルシネーションを防ぐことはできない)。「LHTM-2」は出力が事実に基づいているかを内部的に判断する機構を装備し、ハルシネーションを防いでいる。
パラメータやビッグデータの数では「LHTM-2」と「GPT-3」は同等。同様の規模で学習したモデルとなっている。ただ、最新版の「GPT-4」と比較するとデータ量では「LHTM-2」が劣るが、ビジネス上で重要な「事実性の担保」や「カスタマイズ性」では、変わらず「LHTM-2」の評価が高いとしている。
対話型AIが普及した未来・・
対話型AIに対して恐怖感や嫌悪感を抱く人も多い。AIに支配される人類のディストピアを想像するのかもしれないし、近い将来、自分の仕事がAIに奪われると悩むのかもしれない。それに対して西川氏は個人的な所感としながらも「文章を書くのも読むのも苦手な人はいます。ある意味で、テキストを読み書きする文化を私達は押しつけられてきたとも言えるでしょう。そんな苦手で面倒なことはコンピュータに代替させてもよいのではないか」と語った。そして、「文章に限らず、絵や音楽も生成系AIが作るようになり、自動化はこれからも急速に進むと思います。しかし、人間が伝えるべき仕事、共感性が必要だったり、その人でないとできない特殊な仕事は残り、それ以外のシンプルな作業は、AIがおこなう割合が増えていくと感じています。
ただし、大規模言語モデルは、入力された文章に対して条件反射的に返しているに過ぎず、人間がおこなっているような、なんらかの仮説に基づいて推論したり、正しいかどうかを検証したりはできないため、これを「知性」と呼ぶことはできません」と続けた。
AI GIJIROKUの要約
「AI GIJIROKU」が要約した取材のサマリーを最後に紹介しておこう。オルツ社への今回の取材は、同社のAI議事録サービス「AI GIJIROKU」が稼働して記録していた。AIによる要約のため「AI GIJIROKU」では参考としてこのような要約が出てくる。記事では取り上げなかった事柄が(一部誤字もあるものの)要約されている。
慶應義塾大学大学院政策・メディア研究科修士課程修了。
奈良先端科学技術大学院大学博士後期課程修了。IE Business School 修了。博士(工学)、MBA。
日本電信電話株式会社にて自然言語処理の基礎研究から商用開発、実用化まで一貫して従事。
東京工業大学情報理工学院にて助教として人工知能の研究開発を実施。
データコンサルティングベンチャーにて執行役員として従事後、現職に至る。
「AIコールセンター」のオルツ、クラウド型コールセンターシステム「BIZTEL」と協業開始 AIが電話で自動応答するボイスボットの普及を加速
デジタルクローン/パーソナル人工知能のオルツ、大広と資本業務提携を締結
株式会社オルツ