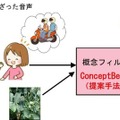
NTTは、複数の話者や話題が混在した音声信号から、話している内容が画像や音声などで指定した「意味」に適合する音声信号を分離抽出する技術を考案した。
この技術は、これまでの手法で用いられていた音の到来方向などに依存することなく適用できるという利点があり、複数の音声が混在した信号から話されている内容に基づいて目的の音声を取り出すことができる世界初の技術となる。
話者が話している意味的な内容を手がかりにして目的の音声を取り出す
近年、音声認識や音声情報からの情報抽出の技術が盛んに活用されるようになっている。人間は、にぎやかな場所であっても、話している人や話題に注意を向けて話を聞き取ることができるが、コンピュータにとっては目的とする音を他の音から分けて聞き取ることは必ずしも簡単ではない。
複数の音源からの音(人の話し声など)が混ざっている音響信号から目的とする信号を取り出す技術は「音源分離」と呼ばれ、これまで数十年間にわたって研究が進められてきた。
従来の音源分離の研究では、信号を分けて取り出すための手がかりとして、「音の聞こえる方向」、「声の高さ(基本周波数)」、「音源(話者)の特徴」、「信号の独立性など」が用いられてきた。これらは総じて、信号自体の物理的特徴に着目したものと言える。
例えば、NTTが開発した複数の声や音が混ざった音から、声の特徴に基づき “聞きたい人の声” を選択的に抽出する技術の一つである「SpeakerBeam」は、指定した話者(Speaker)の声の特徴を手がかりに、話者特徴空間において信号の抽出のビーム(Beam;感度の方向)を向け、信号を選択的に取り出す技術となる。
NTTでは、このように物理的特徴に基づく音源分離の研究を行う一方で、コンピュータによって、データから「意味」を取り出す「概念獲得」と呼ぶ研究を進めており、今回これらの研究成果を融合し、話者が話している意味的な内容を手がかりにして目的の音声を取り出すことができる、新しい音源分離技術を開発した。
「概念フィルタ」を用いるConceptBeam
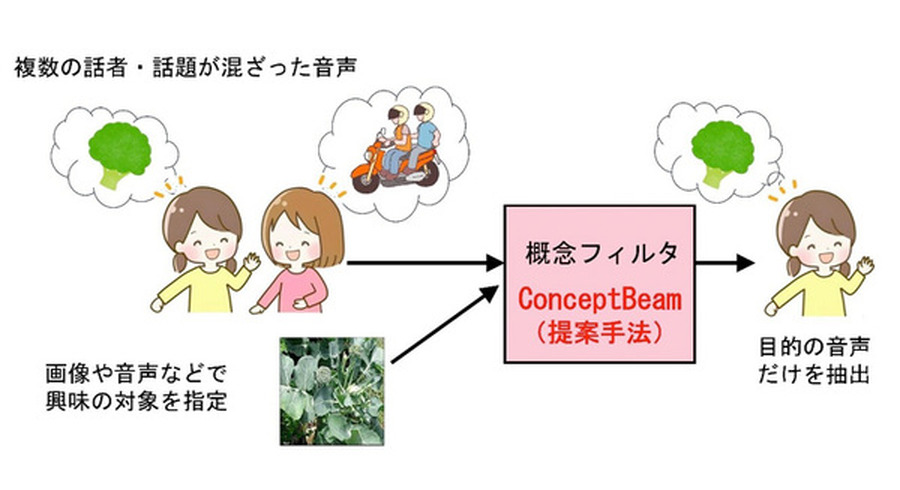
今回開発した音源分離技術は「ConceptBeam」と名付けられた。これは、「指定した意味内容(Concept; 概念)」に「適合する音声を抽出する技術」、つまり特定の概念を通過させるフィルタ「概念フィルタ」であることを表している。
ConceptBeamはシステムに対して、画像や音声などで興味の対象を指定しておくと、入力された混合音の中から、指定した興味の対象に適合する信号を抽出することが出来る。下図の例では、ブロッコリーに関する話とバイクに関する話が混合した音声が入力されたとき、ブロッコリーの画像を手がかりとして指定すると、ブロッコリーに関して話している音声だけを選択的に抽出できる。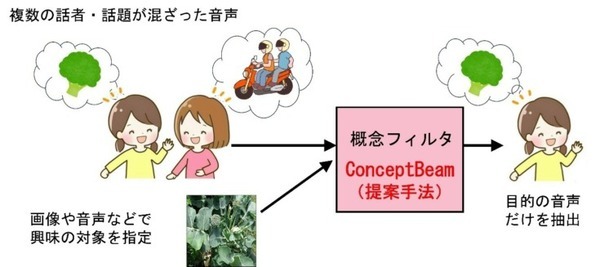
概念の表現
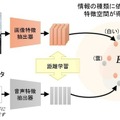
概念の情報をコンピュータで扱うため、概念をベクトル(数値の組)で表すことにする。概念のベクトルが配置される空間を「特徴空間」と呼ぶ。このような特徴空間は、「関連があることが予めわかっている異なる種類の情報」を用いて作ることが出来る。
例えば、下図にある写真の風景を見て、ある人が「青い空、白い雲の下に大きな風車が見えますね」と話した音声があったとする。風景を見てその場で話しているため、この画像と音声には関連があると言る。つまり「関連があることが分かっている異なる種類のデータ」ということになる。これらの画像や音声を、それぞれ「画像特徴抽出器」、「音声特徴抽出器」という2つのニューラルネットワークを用いて画像や音声などのデータから、目的に応じた情報を取り出す特徴抽出を行う際に、関連があると分かっているデータは互いに近くに、そうでないデータは離れるように、という基準でニューラルネットワークを訓練する。ある程度多くの量のデータで訓練すると、情報の種類によらず、「白い」「雲」「風車」といった、同じ概念が近くに配置された空間が構築される。これは同時に、それぞれの情報の種類に対する特徴抽出器が得られていることに相当する。この特徴抽出器を用いると、元のデータの種類にかかわらず、そのデータに表現された概念が類似していれば類似する特徴をいくつかの数値で表現した特徴ベクトルに変換できるようになる。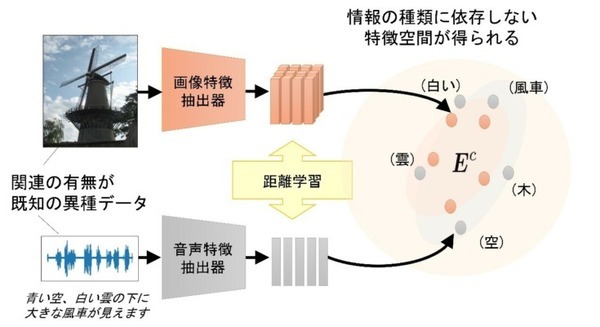
目的音声の抽出
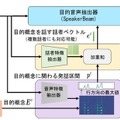
目的音声を抽出するための信号のフィルタリングには、前述のSpeakerBeamを応用している。
SpeakerBeamは、混合音声から、話し手の声の特徴、つまり話者ベクトルに着目して、ある話者の音声を抽出することができる音源分離技術。ConceptBeamでは、新たに、指定された概念に適合する発話区間を検出し、その発話区間に対応する話者の音声を抽出する方法を考案。
この方法では、まず、概念を指定する信号および混合音声からそれぞれ特徴ベクトルを抽出し、これらの特徴ベクトルの類似度を計算することで、「混合音声のどの時間区間が指定した概念に類似しているか」を検出する。続いて、検出された時間区間において「どの話者が発話しているか」を検出し、この話者を表現する特徴ベクトルを抽出する。この話者特徴ベクトルを用いて混合音声から目的音声抽出を行うことにより、指定された概念について発話している話者の音声を抽出する。このとき、話者や話題が複数であっても処理することができる。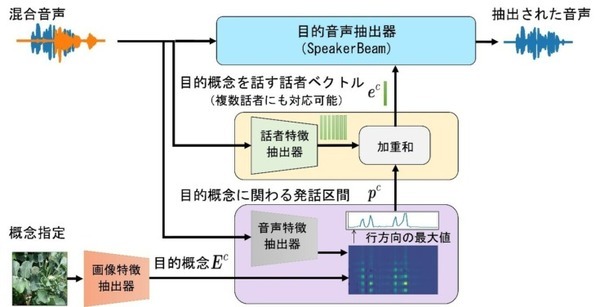
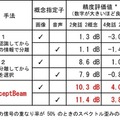
本技術を評価するために、異なるテーマを含む複数話者による混合音声を所定の重なり率で作成し、画像または音声で指定した概念に適合する音声を抽出する実験を行った。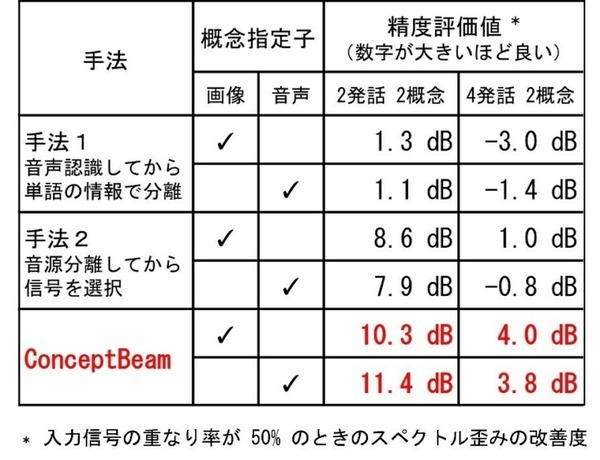
精度評価値とは、混合された元の状態に比べて目的とする信号をどの程度の精度で抽出できたかを表す数値(スペクトル歪みの改善度(音声をどの程度正確に分離できたかを評価するための数値))のこと。
表に示されるように、混合音声に対して音声認識を行う方法(手法1:音声認識してから単語の情報で分離する)および混合音声を音源分離する手法(手法2:音源分離してから信号を選択する)と比較して、本技術では高い精度で目的の音声を抽出できたことがわかる。
今後NTTは信号処理やパターン処理に意味処理を導入し、多種の情報に対して興味のある情報を高速かつ的確に特定し、取り出し、活用できる社会の実現をめざすとしている。
日本電信電話株式会社