




GoogleのAI Blogに、AIが動物の動きを模倣することでロボットの動きを学習し、バランス制御ができるようになる技術が詳しく紹介された(英語「Exploring Nature-Inspired Robot Agility」)。詳細は当該ブログページを読んでいただきたいが、このブログは大きく分けて「動物を模倣することによってロボットが移動スキルを学習」と「人間の労力を最小限に抑えて実世界を歩く学習」で構成されている。前半はまず、AIの学習には「模倣」が重要であり、強化学習と模倣が今後のロボット制御技術の進展のひとつのキーになっていることが分かる。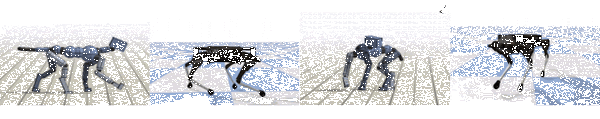
「教師あり学習」と「強化学習」
Google AIブログの投稿は、Googleロボティクス開発に携わる学生研究者のJason Peng氏によるもの。「犬がボールを追いかけたり、馬が障害物を飛び越えるなど、動物は驚くほど豊かなスキルを素早く簡単に習得し、俊敏に行うことができる」という一節から始まっている。
行動にブログミングが必要なロボットにおいてはこれまで、そう簡単にはプログラミングできない、というのが定説だった。その常識を打ち破ったのが「AI」技術だ。
ただ、AIと言っても様々な学習方法がある。最も有名なのは「教師あり学習」だ。画像や動画を識別するAIの学習にも利用されている。例えば、写真に「猫」と「犬」のどちらが写っているのかを判別する例が知られている。AIは膨大な数の「猫」と「犬」の写真や動画を解析するが、そのときラベルと呼ばれる正解(猫の写真には「猫」、犬の写真には「犬」)がラベル付けされていて、AIはその正解を見て、その特徴量を解析・学習していく。AIはあっという間に学習できるとは限らず、「教師あり学習」のために膨大なデータを作成する時間やコストは効率的でない場合や、学習が見込めないことも多い。
その一例がロボットの制御スキルだ。ロボットが転倒したり、バランスを崩さないように制御することは「教師あり学習」は向いていない。
Google AIブログで紹介されているロボット制御の学習方法は「強化学習」(RL: Reinforcement Learning)と呼ばれるものだ。決して最先端の技術というわけではなく「アルファ碁」の学習でも使われた。
「強化学習」には正解が書かれたデータは必要ない。その代わりに「報酬」が必要になる。報酬とはテレビゲームで言えば得点のようなもの。AIは学習する上で何が正しいのか、間違っているのかが分からないので、報酬という形でそれを教えてあげることになる。シューティングゲームで言えば、自身が撃った弾が敵に当たれば得点、敵が撃った弾が自分に当たれば減点。それによってAIは「敵の弾に当たらずに、いかに自分の弾を敵に当てるか」が学習すべき内容だということを理解し、適切な行動を学習していく。
強化学習は膨大な学習データを供給するだけなので、研究者にとっては時として効率的な学習方法だと言える。しかし、ロボットに学習させたいことに対して適切な報酬を設定できなかったとすれば、それは困難な道のりになってしまう。
「強化学習」と「模倣」
何かの行動スキルを学習しようとしたとき、人間ならどうするだろうか?
まずは「模倣」してみるだろう。人間は実に模倣する能力に長けている。縄跳びをしたり、開脚前転をしたり、多くのことを先生や先輩の動きを見て、模倣によって成功と失敗を学習していく。
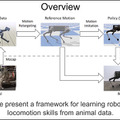
ロボットの学習も、特に強化学習においてこの模倣が重要だ。Google AIブログでは、ロボット(AI)が実際の動物の動きを模倣して、速歩や転回、スキップなど、流暢な動きを生み出すことを学習していくプロセスが紹介されている。

> GoogleのAI Blog「Exploring Nature-Inspired Robot Agility」
動物を模倣してロボットが歩行スキルを学習
ブログの「動物を模倣することによってロボットが移動スキルを学習」では、動物(この場合は犬)の動きから生成・記録されたモーション動画を参照し、強化学習を使って学習するプロセスが語られる。
モーションの模倣
さまざまな歩行スキルを実行している実際の犬のモーション動画を収集し、強化学習を使用して、犬の動きを模倣する制御ポリシーをトレーニングする。ポリシーは物理シミュレーションでトレーニングされ、各タイムステップでモーション動画のポーズを追跡。次に、報酬関数でさまざまなモーション動画を参照することで、さまざまなスキルを模倣するようにシミュレーションロボットをトレーニングする。
すなわち、動物の動きを撮ったモーション動画を分析して、トレーニング用のシミュレーション動画を作成、それをAIが模倣することで動きのプロセスを学習していく。実際のロボットに反映させる際に、ロボットの質量や摩擦などのさまざまな物理量を加味したシミュレーションが行われる。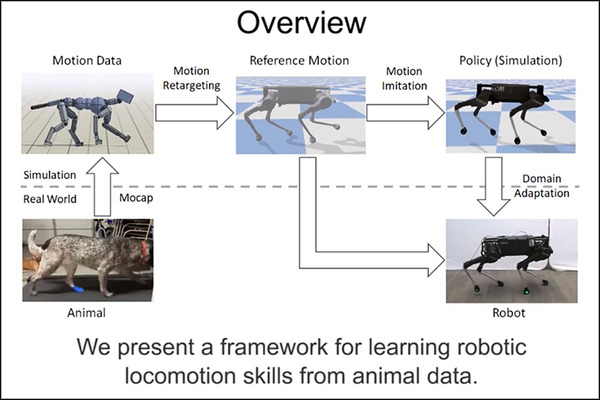
> GoogleのAI Blog「Exploring Nature-Inspired Robot Agility」
ブログでは実際のロボットへの適応前後の比較例を紹介している。ロボットに適応した際に実世界のロボットはバランスを崩して転倒する可能性は十分にあるが、トレーニングで学習した物理的な諸元を設定に追加することで、ロボットは犬のさまざまな歩行スキルを模倣することを学んでいく。
後半の「人間の労力を最小限に抑えて実世界を歩く学習」ではシミュレーションで学ぶだけではなく、ロボットが実体験から学ぶ方法も紹介される。前進と後進、地面が平面と凸凹など、さまざまな環境でのトレーニングプロセスを紹介している。
> GoogleのAI Blog「Exploring Nature-Inspired Robot Agility」
