ディープラーニングとGPUの世界最大規模のイベント「GTC 2021」が開幕し、トップランナー達によるセッション(セミナー講演)が連日行われている。また、NVIDIAの創業者のひとりであり、CEOのジェンスン フアン氏(Jensen Huang)の基調講演も予定通り行われ、日本語字幕版も公開されている。
そんな中、「NVIDIAがCPUに本格参入」という発表によって業界内は騒然としている。CPUの名前は「Grace」。エネルギー効率が高いArmコアを使用し、巨大なAIモデルをトレーニングするシステムに最適なハイパフォーマンス・コンピューティング向けのCPUで、NVIDIAは、従来の同環境で採用されている「x86 CPU」と比較して10倍のパフォーマンスを実現するとしている。
既に、スイスのスーパーコンピューティングセンターと米国エネルギー省のロスアラモス国立研究所がこのCPUを搭載したスーパーコンピュータを構築していることも発表した。「Grace」は2023年初頭に発売される予定だ。
低消費電力でハイパフォーマンスCPU 実現の理由
現地時間の4月12日、GTC 2021に合わせて、NVIDIAは複雑なAIとハイパフォーマンスコンピューティングのワークロードにおいて、現在の最速サーバの約10倍のパフォーマンスを提供するArmベースのプロセッサ構成で、データセンター向けの「CPU」を発表した。
そのCPU「Grace」は、自然言語処理、レコメンダーシステム、AIスーパーコンピューティングなど、超高速のコンピューティング・パフォーマンスと大容量メモリの両方を必要とする膨大なデータセットの分析を行う、世界最先端のアプリケーションのコンピューティングの要件に対応するように設計されたとしている。
その特徴のひとつはエネルギー効率の高いArm CPUコアを採用し、低消費電力のメモリ・サブシステムと組み合わせることで、更にエネルギー効率に優れた設計を追求、それでいて高いパフォーマンスを実現していることだ。
NVIDIAと言えば「GPU」で知られ、GPUは今やディープラーニングなどのAIコンピューティングに必須のものになっている。データセンター向けのハイパフォーマンスコンピューティングでも複数のGPUを回して演算能力のフル活用を目指しているものの「CPU」がボトルネックになるケースも出てきている。
NVIDIAはその点に着目して、複数のGPU活用に最適なCPUの開発をArmベースで行ってきた。
NVIDIA が Grace CPU を導入するのは、データの量とAIモデルのサイズが急激に増加しているため。今日の最大のAIモデルには数十億のパラメーターがあり、2か月半ごとに倍増しているという。それらをトレーニングするには、システムのボトルネックを解消するためにGPUと緊密に結合できる新しいCPUが必要と判断した。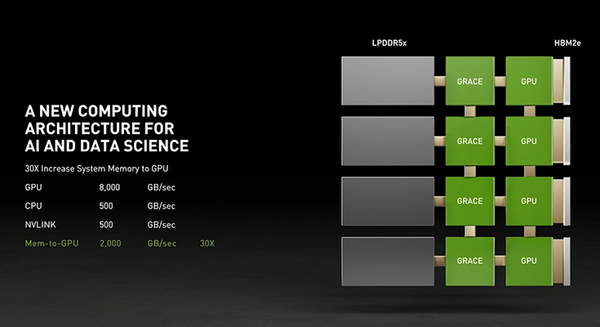
NVIDIA は、Armが培ってきたデータセンター・アーキテクチャの優れた柔軟性を活用することにより、高速化のためにゼロから設計されたCPU「Grace」を開発。NVIDIAは、新しいサーバークラスのCPUを導入することで、最も難しい課題を解決するイノベーションを提供する鍵「AI および HPC コミュニティにおけるテクノロジーの多様性という目標を推進」するとしている。
基調講演の中でこのしくみについて、ジェンスン フアン氏は次のように説明している。
ジェンスン フアン氏
CPU メモリは1TBと大容量ですが、0.2TB/秒は低速です。
CPUメモリはGPUメモリと比較すると3倍の容量がありますが、速度は40分の1になってしまいます。このノードの1,320GBメモリの全てを活用してAIモデルを学習させるのが理想的ですが、そううまくはいきません。CPUメモリを高速化し、4つのチャネルをCPUに接続して、各GPU専用チャネルとするのです(図A)。しかし、これをパッケージ化できてもPCleがボトルネックになってしまいます。そこでNVLinkの出番です。NVLinkには十分な速度があります。しかし、x86 CPUにはNVLinkがなく、4つのNVLinkを使用することはできません。
そこで、本日紹介するのは初のデータセンター向けCPUであるProject「Grace」です。GraceはArmベースで、AIなど大量のデータのアクセラレーテッドコンピューティング向けに設計されています(図B)。GraceではArmの特長が活用されています。IPモデルにより、この用途に最適なCPUの構築が可能になり、従来よりさらに高速化されました。GraceのArmコアは次世代のサーバー向け市販用IPです。1つのGrace CPUあたりのSPECintベンチマーク性能は300を超えています(合計で2,400以上)。従来の8つのGPU DGXのSPECintベンチマーク性能は450です。(Graceでは、2400のSPECing_rateが可能で、現在の最高性能のDGXのSPECint_rate値の450をはるかに凌駕する)。システムとメモリの帯域幅が劇的に向上します。
■ジェンスン フアン氏による「GTC2021」基調講演(日本語字幕可) Graceの解説パート
Graceの最初の採用が科学と AI の限界を高める
NVIDIA、Arm、そしてこのシステムの採用を決めて構築を行っている担当者たちは次のようにコメントを寄せている。
ジェンスン フアン氏
最先端の AI とデータサイエンスは、現代のコンピューター アーキテクチャの限界を押し広げており、考えられないような大量のデータ処理が可能になっています。Arm の IP ライセンシング モデルを使って、NVIDIA は、巨大なスケールの AI とHPC を想定した CPU である、Grace を開発しました。GPU と DPU と組み合わせることで、 Grace は NVIDIA にとってのコンピューティングの第 3の基盤技術となり、AI を発展させるためにデータセンターを再構築できるようになります。NVIDIA は現在、3 種類のチップを提供する企業となりました
Arm の CEO であるサイモン シガース(Simon Segars)氏 は次のように述べている。
サイモン シガース氏
「世界で最も広くライセンスされているプロセッサ アーキテクチャとして、Arm は日々驚くほどの新たな方法でイノベーションを推進しています。NVIDIA による Grace データセンター CPU の発表は、Arm のライセンシング モデルがいかに重要な発明を可能にするかを明確に示しています。これは、あらゆる場所の AI 研究者や科学者の素晴らしい仕事をさらにサポートするものです」
NVIDIAは今回のリリース時に、スイス国立スーパーコンピューティング センター(CSCS)と米国エネルギー省のロスアラモス国立研究所が、国の科学研究活動を支援するために「Grace」を搭載したスーパーコンピュータを構築する計画を発表したことも紹介している。
CSCSとロスアラモス国立研究所はどちらも、「Grace」搭載のスーパーコンピュータをHewlett Packard Enterpriseで構築。2023年には稼働させる予定だ。
CSCS のディレクターであるトーマス シュルテス教授 (Prof. Thomas Schulthess) は次のようにコメントしている。
トーマス シュルテス教授
「NVIDIA の新しい Grace CPU を使用すると、AI テクノロジーと従来のスーパーコンピューティングを統合して、計算科学における最も困難な問題のいくつかを解決できます。私たちは、大規模かつ複雑な科学データセットを処理および分析するために、新しい NVIDIA CPU をスイスや世界中のユーザーが利用できるようになることを嬉しく思います」
ロスアラモス国立研究所所長のトム メイソン氏 (Thom Mason) のコメントは次の通り。
トム メイソン氏
「メモリ帯域幅と容量の革新的なバランスにより、この次世代システムは私たちの機関のコンピューティング戦略を形作るでしょう。NVIDIA の新しい Grace CPU のおかげで、忠実度の高い 3D シミュレーションを用いた高度な科学研究や、これまでよりも大規模なデータセットを用いた分析が可能となります」
「Grace」ベースのシステムは、「x86 CPU」で実行されている現在の最先端をいく「NVIDIA DGX」ベースのシステムよりも10倍速いとしていて、1兆パラメータのNLPモデルのトレーニングも可能としている。
このパフォーマンスの根底にあるのは、第4世代の NVIDIA NVLink 相互接続テクノロジーであり、NVIDIA Grace CPUと NVIDIA GPUの間で900 GB/sの接続を提供し、今日の主要サーバーと比較して30倍高い総帯域幅を実現する。
Grace は、革新的な LPDDR5xメモリ サブシステムを採用し、DDR4メモリと比較して2倍の帯域幅と10倍優れたエネルギー効率を実現。さらに新しいアーキテクチャは、単一のメモリ・アドレス空間で統合されたキャッシュ コヒーレンスを提供し、プログラマビリティを簡素化するためにシステムと HBM GPUメモリを組み合わせる。
NVIDIA Grace CPU は、NVIDIA HPC ソフトウェア開発キットと CUDAR および CUDA-Xライブラリの完全なスイートによってサポートされ、2,000を超える GPUアプリケーションを高速化し、世界で最も重要な課題に取り組んでいる科学者や研究者の発見を加速したい考えだ。
登場が今から待ち遠しい。
NVIDIAとBMWが作る「デジタルツイン」の自動車工場を紹介 人と協働ロボットの計画プロセスを30%効率化【GTC 2021】
NVIDIAとアストラゼネカが協業 創薬におけるAIの活用を支援 有望な新薬のいち早い発見のため必要なツールを研究者に提供
ソフトバンクが「NVIDIA Maxine」とMECで5G通信の映像を「超解像」化する実験に成功 ウェブ会議の画質を向上する技術
NVIDIAがデータセンター向けCPUに本格参入へ ArmベースのCPU「Grace」発表 並列GPUで「x86」の10倍高速化できる理由
NVIDIAが5GとAIエッジ「AI-on-5G」や自動運転車向け最新「NVIDIA DRIVE Atlan」、連携企業などを発表【GTC2021】
「GTC 2021」関連記事 (ロボスタ)