


日本電信電話(NTT)は、クルマから見える移り変わる景色を話題に会話できる、まるでパートナーのような知識応答や共感応答をする対話AIを開発した。
従来からある対話システムの大半は、話者が発話するテキスト情報に対して適切に会話を返すものが多く、周囲のリアルタイムな画像情報や位置情報に応じて返答するシステムはなかった。
この対話AIは、NTTが構築した深層学習に基づく大規模テキスト対話モデルを、ドライブ中の対話データ・周辺情報データを用いて追加学習し、景色として見える画像情報や、関連する外部知識に基づいて、自然に対話する機能を持つ。
例えば、下記のような対話が可能という。
今後は、日常的なドライブのパートナーをめざして、日々繰り返される対話への適用や、居眠り運転・漫然運転防止の実証実験に取り組む。この成果は、6月2日よりオンラインで開催される、コミュニケーション科学基礎研究所オープンハウス2022で出展される予定。
テキストだけでなく景色や位置情報も話題に組み入れるAI
NTTは、人の日々のコミュニケーション・パートナーAIの実現をめざし、対話を通して人の興味や思考を引き出したり、人の対話欲求を充足したりする、雑談対話AIの開発に取り組んでいる。
近年の深層学習技術の進展によって、対話AIの性能は急激に向上しており、NTTでも日本語最大規模の学習データを用いた高性能日本語対話AIを構築している。
一方、従来の対話AIの課題としては、入力できる情報がテキスト情報のみに限られる点が挙げられる。日々のコミュニケーション・パートナーをめざす上では、私たちの身の回りの実際の状況を理解し、対話に取り込むことが求められる。
こうしたことを背景にNTTは、クルマなどの移動体から見えて、移り変わる景色を話題として、パートナーのように知識応答や共感応答をする対話AIを実現した。常に自己位置が変化する状況下で、自己の周囲の景色やそこに紐づく情報に基づく雑談対話を行う対話AIは、世界で初めて実現された成果、としている。
技術のポイント
1. 世界最大規模の対話データで学習した深層学習ベース対話モデルの利用
NTTは、超大規模Web対話データ・高品質対話データと、近年進展が著しい深層学習技術(Transformer Encoder-decoderモデルを組み合わせることで、日本語最大規模の対話モデルを構築した。構築した対話モデルは、ルールや係り受け関係などの統計情報に基づく従来のモデルに比べ、抜本的に異なるレベルで複雑な文脈の理解や自然な発話の生成を実現しており、雑談AIの性能を競う対話システムライブコンペティション3でも圧倒的な成績で優勝するなどの成果を挙げている。また、検証・評価目的に限定して対話モデル・対話データを無償公開しており、構築したモデルの幅広いフィールドでの効率的な検証を進めるとともに、日本語対話AI研究の地位向上にも寄与している。
なお「Transformer Encoder-decoderモデル」は、Google Researchが開発し、2017年にオープンソース化したニューラルネットワークのアーキテクチャ。機械翻訳や対話アプリケーション等、文と文の変換を行う言語モデルに多く適用されている。
https://github.com/nttcslab/japanese-dialog-transformers
2. 自己位置周辺の景色画像・外部知識の同時導入
大規模対話モデルは、テキスト情報のみを入力として扱っている。そのため、テキストに閉じた対話では非常に自然な雑談を実現できているものの、私たちが普段行っている、実際の周辺の状況に応じた対話を行うことは困難となる。
例えば、人とドライブを楽しむ対話AIを実現するには、自己位置周辺の景色画像や外部のスポット情報を適切に処理しながら、対話に反映させる必要がある。
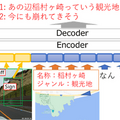
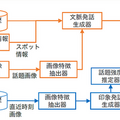
NTTはこの課題に対し、画像内の物体の情報と、自己位置周辺のスポット情報を大規模対話モデルに導入する技術を開発した。画像内に写っている物体群については、物体検出と呼ばれる技術を用いて抜き出し、それぞれを大規模対話モデルで扱える数値情報(埋め込みベクトル)に変換して入力する。またスポット情報については、自己位置近傍のレストラン等のスポットに関する情報(ジャンル・名称等)をテキスト形式で取り出し、対話の文脈と同様の形式で入力する。大規模対話モデルはこれらの入力情報に基づき、それらを反映した対話AIの発話を出力する。
このように設計したモデルを、ドライブ対話データ(運転画像を見ながらガイド役・ドライバー役の間で行った対話)で学習することで、自己位置周辺の景色画像・スポット情報に基づく発話生成を実現した。
3. 連続的に変化する画像情報に基づくリアルタイム対話制御
ドライブ中の自己位置は次々に、連続的に変化する。対話AIは、人がどの時点の画像やスポット情報を話題としているのかを理解しつつ、新規に入力された情報にも適切なタイミングで触れながら対話する必要がある。
この成果では、対話の文脈からの話題となっている画像の推定と、次々に入力される画像に対する発話の話題強度の推定技術を開発した。それらを適切にタイミング制御に組み込む。これによって、ユーザの発話に自然に応じながら、ユーザが強く興味を惹かれるであろう情報を適切なタイミングで提供する、新感覚のドライビング・パートナーとなる対話AIを実現した。
今後の展開
今後、日常的なドライブパートナーをめざして、繰り返される対話への適用や、外部知識のさらなる利用に取り組む。また、長距離運転時の居眠り運転・漫然運転の防止や、自由な会話で検索可能な音声ナビゲータの実現をめざし、実車・VR等での実証実験を進めていく。





