




rinna株式会社が、日本語に特化した画像生成モデル「Japanese Stable Diffusion」を公開した。また、このモデルを活用できる画像生成サービスの提供も開始した。
「テキスト文字」を入力すると、連想される画像をAIが描画生成する技術が話題を呼んでいる。一方で、多くのサービスで「テキスト文字」は英語等の外国語に限定されていて、日本語での指定には対応していない。今回のrinnaの発表は、日本語のテキストに対応し、日本語固有の表現を理解できる画像生成AIサービスが登場したことを意味する。
早速、編集部でも体験してみた結果は・・・
「Stable Diffusion」とは
話題になっている「AIが画像を生成するタスク」において「Diffusion Model」は一部で高い評価を得ている。一般的に「Diffusion Model」を基にした テキスト条件付き画像生成モデルでは、テキストを解釈するテキストエンコーダーと、そのテキストエンコーダーの出力から画像を生成するモデルの2つから構成される。
Stability AI社により公開されたテキスト条件付き画像生成モデルである「Stable Diffusion」はテキストエンコーダーとしてOpenAI社によって学習された事前言語画像モデル CLIPを利用し、生成モデルには Diffusion Modelの改良版である「Latent Diffusion Model」を用いている。
学習時には、テキストエンコーダーである CLIPのパラメータは固定し、生成モデルである「Latent Diffusion Model」のみを更新することで、OpenAI社の優れた CLIPを活かす。「Stable Diffusion」の学習データには、LAION-5Bの英語サブセットである23億枚のキャプション付き画像が用いられており、テキストプロンプトを入力するだけで高性能な画像を生成することができる、としている。また、高性能であるにも関わらず、10GB VRAM GPU程度のコンピューティングコストで推論が動作し、手軽に使用できるという特徴もある。
Japanese Stable Diffusionの開発背景と特徴
「Stable Diffusion」は、英語のキャプション付き画像から学習されているため、日本語から画像を生成するためには、英語に翻訳したテキストプロンプトを用意する必要がある。しかし、日本語固有の表現(例えば固有名詞、和製英語、オノマトペは、翻訳が難しく、画像生成に反映させることは困難だ。また、学習データの多くは英語圏の画像であり、英語圏の文化を色濃く反映した画像が生成される、という傾向がある。
そこで同社では、日本語に特化した画像生成モデル「Japanese Stable Diffusion」を開発することでこの課題を解決した。
Japanese Stable Diffusionの特徴
このモデルには下記の特徴がある。
・学習データとして、 LAION-5Bの日本語 サブセットをはじめとした約1億枚の日本語 キャプション付き画像を利用。
・日本語のテキストプロンプトに対応させるために、Stability AI社が公開したStable Diffusionの生成モデルパラメータを固定し、テキストエンコーダーのみ日本語キャプション付き画像を用いて追加学習を行なった。その後、テキストエンコーダーと生成モデルのパラメータを同時に更新する追加学習を行うことにより、さらに日本語の画像生成に最適化した。
・学習された「Japanese Stable Diffusion」は、Stable Diffusionのライセンス CreativeML Open RAIL-Mを継承し Hugging Faceにて公開した。
・劇的に進歩するAI分野において、英語圏の進歩に追随するために早期にモデルを公開した。
日本語のテキストプロンプトから生成された画像のサンプル
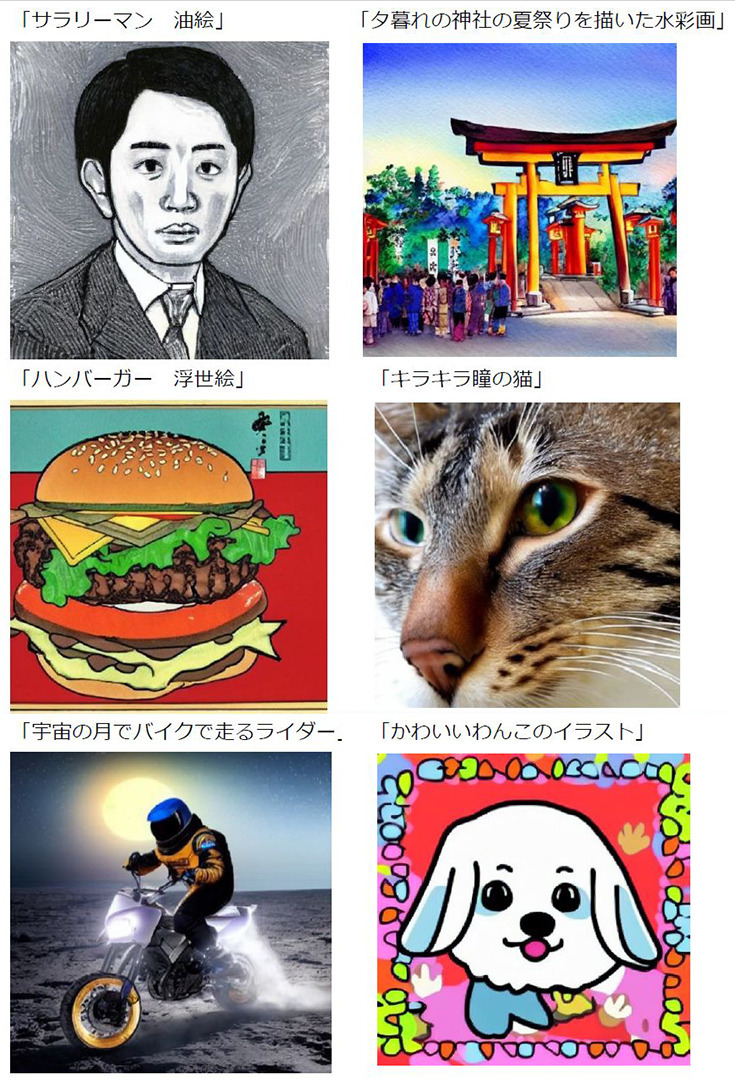
AI画像生成が注目を集める
これまで同社は、日本語に特化した言語モデル「GPT」「BERT」や言語と画像の関係を表現する言語画像モデルCLIPなどを公開し、研究・開発者が利用してきた。
また、2022年の春以降「DALL-E 2」「Midjourney」「Stable Diffusion」といった精度の高いAI画像生成が話題となっている。このたび同社は、Stability AI社がオープンソースで公開する画像生成モデル「Stable Diffusion」に日本語のキャプション付き画像を用いて追加学習することで、日本語に特化した画像生成モデル「Japanese Stable Diffusion」を開発した。
このモデルにより、テキストプロンプトとして日本語を考慮し、翻訳では表現が難しい日本語圏の文化を反映した画像生成を実現できるという。そして AIモデルライブラリ「Hugging Face」と「GitHub」でこのモデルを公開することにより、言語・画像の研究・開発 コミュニティに還元する。
・Hugging Face
https://huggingface.co/rinna/japanese-stable-diffusion
・GitHub
https://github.com/rinnakk/japanese-stable-diffusion
「Japanese Stable Diffusion」の体験方法
『キャラる』やSNSで「Japanese Stable Diffusion」の画像生成を体験
同社の運営するサービス『キャラる』やSNSにもこのモデルを実装し「Japanese Stable Diffusion」の画像生成が体験できるようになった 。配信中のAIキャラクターSNS『キャラる』では、「お絵描き上手」などのバッジをAIキャラクターに付与することにより、 AIキャラクターが自発的に「Japanese Stable Diffusion」での画像生成を行う。
また、『キャラる』の公式Discordでは「 # |aiお絵描き 会場」 のチャンネルを開設し、 botの「Tsukuru(ツクる)」を呼び出すことで日本語で入力したプロンプトから画像の生成を行うことができる(※利用規約への同意が必要)。
・『キャラる』公式サイト
https://www.chararu.jp/
・『キャラる』公式(discord)
https://tinyurl.com/chararu
同社のChief AI Communicatorのりんなの特定のツイートにリプライを送ると「Japanese Stable Diffusion」から生成された画像が返信される。
AIりんな 公式 Twitterで試してみた
Twitterアカウントを持っていれば、AIりんなの公式ツイッターの画像が生成されるアカウントで試してみる方法が簡単かもしれない。下記の「リプライを 送ると 画像が生成される ツイート」にアクセスして、描いて欲しいテーマをテキストでリプライ(返信)すると、(気が向いたら)AIりんながこの技術を使って生成した画像を返してくれる。
Twitterで「タスキがけをしてモーレツに読書をするロボット」と返信したら、下記の画像がAIりんなから返信されてきた。AIっぽいと言えばAIっぽいセンスなのかもしれないが、ちょっと謎すぎる画像が生成されちゃっているので、もう少し品質向上やAIの学習の余地があるようだ。
・AIりんな 公式 Twitter
Tweets by ms_rinna
・リプライを 送ると 画像が生成される ツイート
https://twitter.com/ms_rinna/status/1567844022240313344
rinna DevelopersでAPIを公開
開発者向けに公開しているAPIサイトの rinna Developersでも、このモデルを使用したAPI「Text To Image API v2」を公開した。このAPIを使用することで、「Japanese Stable Diffusion」での画像生成機能をアプリケーション等に実装することができる。
※利用にはユーザー登録とrinna Developersの利用規約への同意が必要。
・rinna Developers
https://developers.rinna.co.jp/
画像生成モデル「Japanese Stable Diffusion」が人々の創造性を後押し
rinnaは「人とAIの共創世界」をビジョンに掲げている。人と人との間にAIが介在することで豊かなコミュニケーション環境を実現し、すべての人が自分らしい創造性を発揮できる社会を目指す考えだ。
その取り組みの中にあって、画像などの非言語コミュニケーションを重要視し、かねてより AIりんなをはじめとした AIキャラクターが発信する画像生成や、研究成果として学習済みの言語画像モデルを公開してきた。
同社はリリースを通して「rinna社の考える AIとの共存は、「 AIによる人間の創造性の発展」です。「あなたらしい創造力をAIキャラクターと共に引き出し、世界をカラフルに。」をミッションとするrinna社として、このたび公開する画像生成モデル「Japanese Stable Diffusion」が多様な人々の創造性を後押しすることを願っています」とコメントしている。
今後の展開
同社は「今後もAIに関する研究を続け、高性能な製品・サービスの開発を目指します。研究成果については引き続き公開し、研究・開発コミュニティへ還元してまいります。
また、近年では AIモデルを用いた文章生成や画像生成により、魅力的なコンテンツを生み出すためのテキストプロンプトが重要視され、AIの力を最大限に引き出すことのできるスペシャリストを求める動きが活発になっています。 AIも人もいきいきと活躍できる社会を目指すrinna社では、テキストプロンプトを専門に扱うプロンプトエンジニアのポジションを新設し、採用活動を進めています。AIの社会実装を推進するにあたり、rinna社はAIに関わる雇用機会の創出も積極的に行って まいります」と語っている。
なお、プロンプトエンジニアの採用情報 はこちら
https://www.hireplanner.com/ja/frontend/companies/240/jobs/4444
りんな(rinna) AI対話技術の最前線 採択された論文の音声合成技術のポイントと今後の展望をrinnaの研究チームに聞く
【合成音声サンプルを聴いてみよう】音声処理における世界最大規模の国際会議で「りんな」(rinna社)の音声合成技術の論文が採択
【動画】AIりんながついに役職に!rinnaのチーフAIコミュニケーターに就任 7/27-28開催のカンファレンスで登壇
AI初!りんなが『ILLUSTRATION』に選出!GANを応用して生成したりんなの描画が『ILLUSTARION 2022』に掲載
AIキャラクター「ロボコ」と「りんな」がコラボ 「週刊少年ジャンプ」が協力、『僕とロボコ』をAIキャラクター化
「りんな」(rinna)関連記事一覧






