

トヨタ自動車株式会社は、未来創生センターにおけるヒューマノイドロボットの強化学習を活用した運動制御研究の成果を2026年3月31日(火)に公開した。
「歩行」と「バスケットボールのドリブル」という2つの動作習得に取り組んだ内容を報告している。
強化学習とSim2Realの概要
強化学習とは、AIがある環境下で試行錯誤を繰り返しながら、あらかじめ設定された報酬を最大化する方法を自ら見つけ出す機械学習の一種だ。
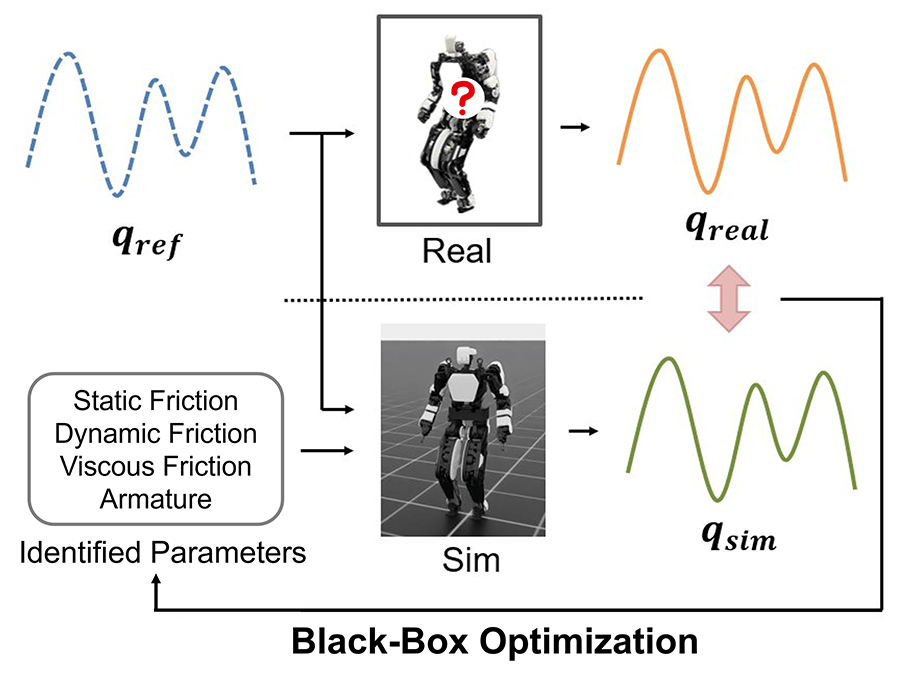
近年はシミュレーション環境でロボットに大量の経験をさせ、その学習結果を実際のロボットに適用する「Sim2Real」という手法が広まっている。同研究では、試験機を用いてこのSim2Realアプローチを歩行とドリブルの両タスクに適用した。
歩行タスクでは、「目標速度に近い歩行だと加点」「足が滑ると減点」という報酬を設定し、シミュレーション上に数千体のロボットを並列で動作させることで、1~2時間程度の学習でバランスを取りながら歩行するところまで習得が可能となった。しかし、シミュレーションと実機の挙動が大きく異なる「Sim2Real Gap」が課題となった。
これに対し、関節の回転量を測るエンコーダや傾きや動きを測るIMUのセンサ値にノイズを加えたり、床の摩擦をランダムに変化させたりして環境のばらつきを再現する「Domain Randomization」を導入。
さらに、実機のアクチュエータを実際に動かして取得したデータをもとにシミュレーションのアクチュエータモデルを最適化する「Real2Sim」にも取り組み、実機での安定した歩行を実現している。
ドリブルタスクへの挑戦とモーションキャプチャの活用
ドリブルは歩行と異なり、ロボット自身の動作に加えて外部環境であるボールを操作する必要がある。
ボールに触れるタイミングが瞬間的であり、動作の選択が非常に難しい課題だ。報酬設計においても、歩行に比べて先行研究が少なく、ボールを適切な速度や方向で打ち出し継続的に接触を維持するための定量的な評価指標の設定が困難だった。
この問題に対し、人間がドリブルをしている動きをモーションキャプチャで記録し、得られた関節角度や動作速度をロボットの骨格構造や可動域に合わせて変換した参照動作データを活用する手法を採用した。参照動作に近づくほど高い報酬を与える条件で学習させることで、自然で安定したドリブル動作の習得に成功した。
また、ドリブルのSim2Realでは、シミュレーションでは正確に取得できるボールの位置や速度を、実機ではカメラと認識アルゴリズムで推定する必要があり、認識誤差や遅延が問題となった。
実環境のカメラ認識の誤差や遅延をモーションキャプチャで評価し、その特性をシミュレーション側にも組み込むことで現実に近い観測環境を再現し、実機でのドリブル成功に繋げた。
研究成果の詳細は同社のサイトからも確認できる。
ロボスタでオンラインセミナーを開催
「AIエージェント × ヒューマノイド 生成AI時代の「Pepper+」徹底解説」
ロボスタではオンラインセミナーを定期的に開催しています。
4月後半はソフトバンクロボティクスが登壇し、「AIエージェント × ヒューマノイド 生成AI時代の「Pepper+」徹底解説」を開催します。

ソフトバンクロボティクスは「Pepper」を2014年に発表、2015年に発売開始、世界初の量産型ヒューマノイドとしてギネス世界記録にも認定されました。身長約120cmの親しみやすいデザインを活かし、会話やダンス、歌といったエンターテインメント用途に加え、観光、介護、教育、小売、イベント、オフィス受付など幅広い分野で社会実装が進められてきました。
このPepperの進化版モデルであり、AIエージェント機能を中核に据えた新世代のロボットプラットフォーム「Pepper+」を2026年に発表しています。生成AIやAIエージェントを活用したヒューマノイドの社会実装の知見を紹介します。
セミナーの詳細とお申し込みはこちら。
人とロボットが共生するこれからの住環境 MWが語る 住宅×フィジカルAI×ロボティクス最前線
5月には株式会社MWの成田修造氏を迎え、「人とロボットが共生するこれからの住環境 MWが語る 住宅×フィジカルAI×ロボティクス最前線」を開催します。
フィジカルAIやヒューマノイドが話題になる中、「ロボットやAIが溶け込む住宅とは何か」という、近い未来に起こる住環境の変革について解説していただきます。

フィジカルAIやロボットが住宅環境にどのような進化を与えるのか。斬新な発想とデザイン、AIやロボットの活用法やビジネスモデルを紹介します。
セミナーの詳細とお申し込みはこちら。