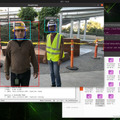

1回目の開封の儀から時間が空いてしまい、お待たせしました。「NVIDIA Jetson AGX Orin」レビュー 第2回をお届けします!
今回は皆さん待望の「Jetson AGX Orin」(以下、Jetson Orin)のベンチマークテストをお送りします。「Jetson AGX Xavier」と「Jetson Nano」と高速性能を比較します。更に、ベンチマークとは別に「TAO toolkit」を体験しましたので紹介します。機械学習を効率化する「転移学習」です。その2本立てでお送りします。
【Jetson AGX Orinレビュー】最新の超小型AIコンピュータ最速レビュー、「開封の儀」歴代Jetsonとの比較やインタフェースもチェック
「Jetson Orin」開発者キットのベンチマーク
早速、「Jetson Orin」のベンチマークを行い、高速性能を見ていきましょう。ソフトウェアは、恒例の「UnixBench」と、「NVIDIAのプレスキットで提供されているbenchmarkツール」を使って進めていきます。
ベンチマークを進めていく矢先に不吉な事態に
早速「UnixBench」でベンチマークの計測を行おうと、手元にあるすべての「Jetson」を動作確認したのですが、なんと「Jetson Xavier NX」が動かないという緊急事態が発生。
「Jetson Xavier NX」の電源を入れてもディスプレイが表示されません。せっかく全てのJetsonをJetPack4.6.1にアップデートしたのに、なんだか早々に残念な展開に・・。
仕方ないので、「Jetson Orin」「Jetson AGX Xavier」「Jetson Nano」の3台での比較でベンチマークをします。
Jetson Orinのベンチマーク計測
ベンチマークは2つの方法で計測しました。ひとつは「UnixBench」で、CPUを中心とした演算性能のチェックです(GPU性能はほとんど影響しません)。もうひとつが「NVIDIA Benchmark」で、GPUの演算性能が結果に反映されるベンチマークです。
UnixBenchでのベンチマーク
UnixBenchではCPUのコア数に関係なく1parellel copyの計測と、全コア数使う”n” parallel copyのテストを行いました。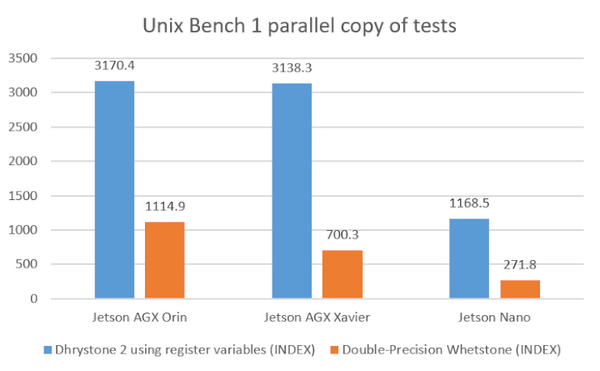
Dhrystone2はCPUの整数演算、Whetstoneは浮動小数点演算の測定をします。GPUは使わないのでベースのCPUがどれくらい違うかの参考程度にはなるかと思います。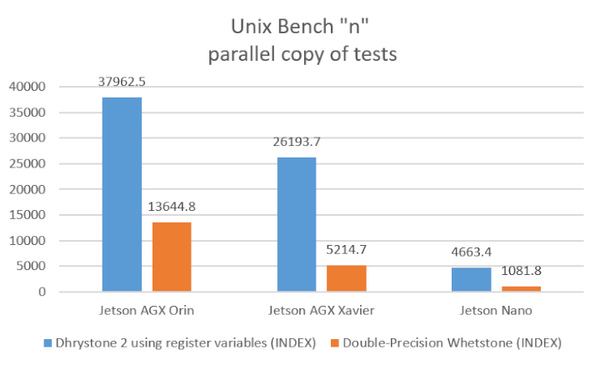
1コア単体で見ると、整数演算では「Jetson Orin」と「Jetson Xavier」ではほぼ同程度、浮動小数点演算では1.59倍くらいのようです。しかし「Jetson Orin」のコア数は12個、「Jetson Xavier」のコア数は8個なので全コアを使った場合では整数演算で「Orin」は「Xavier」の1.4倍、浮動小数点演算では2.6倍の差になります。
Jetson Nanoはエントリーモデルのため、性能面では大きく差が開いた結果になりました。
NVIDIA Benchmarkを使ったAI処理での比較
それでは次に、NVIDIAで提供されているBenchmarkツールを使って機械学習の処理でのベンチマークを計測してみます。
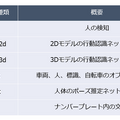
今回提供されているベンチマークは6種類の機械学習処理をつかったベンチマーク計測を行います。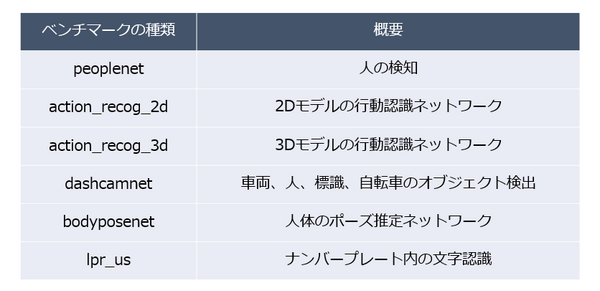
今回Orinと同じベンチマークを動かして比較するため、XavierにもJetPack5.0Early Adapter Programに参加してSDK Manger経由でインストールしました。
SDK Managerを使ったJetPackのインストール方法は今回は割愛しますが、別記事で紹介しているので確認してみてください。
OrinはXavierの2.5~3.6倍高速、ロボットにも最適
ということで、比較した結果がこちらになります。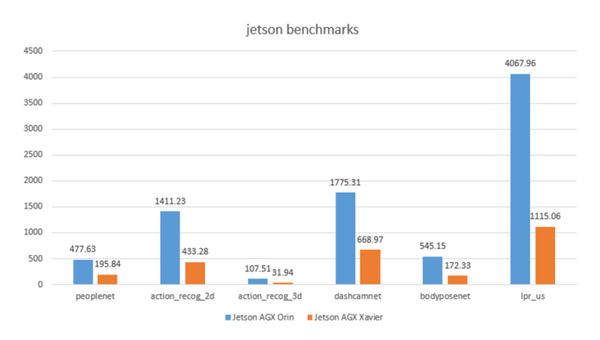
全体的にOrinはXavierの2.5~3.6倍程度高性能なようです。特にlpr_us、ナンバープレートの文字認識の結果が一番差があります。
これを見る限り、「Orin」のAI処理能力は「Xavier」よりも余裕があるため、同時に2~3個のAI処理を動かすことも可能になってきそうです。これはリアルタイム処理の必要性が高い自律運転系のAI処理が多いケースや、複数のセンサーやサーボを同時に制御するロボット開発してるケースには朗報だと思います。
TAO Toolkitトレーニング体験(転移学習)
次は、TAO Toolkitのトレーニング体験をレポートします。TAOプラットフォームの概要を説明してから、実際のToolkitの内容に入っていきます。
TAOプラットフォームの概要
まずはTAOプラットフォームの概要に関して説明しましょう。TAOは、Train Adapt and Optimizeの略称です。
通常、JetsonなどのAIエッジデバイスを実ビジネスで活用する場合、学習モデルを1から作成することになりますが、それには時間と手間がかかります。それ以外の方法として、既存の学習済モデルから学習済の特徴量を新しいモデルのために抽出し、それを転移することで学習コストを抑える「転移学習」という手法があります。「TAOプラットフォーム」はこの転移学習を簡単に扱うためにNVIDIAが用意したプラットフォームです。
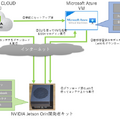
今回、TAOのトレーニング体験で準備してもらった環境の概要は以下の通りです。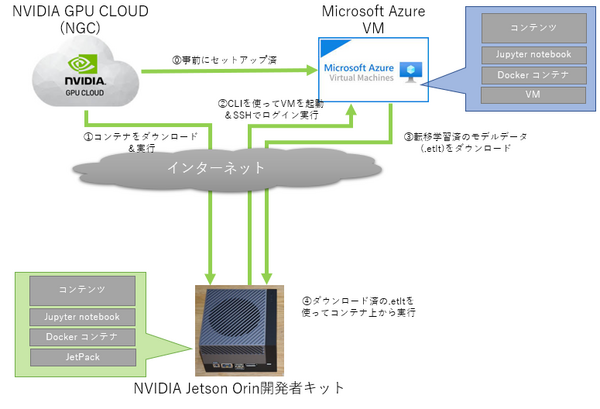
エッジ環境の「Jetson Orin」のほか、今回はクラウド上に転移学習のトレーニング環境をNVIDIAに用意してもらいました。コアGPUとして「NVIDIA V100」搭載のMicrosoft Azureの仮想マシン上に、TAOのトレーニング環境のコンテナがセットアップされたものを準備してもらったので、これを使って転移学習を行いました。
なお、「NVIDIA V100」はデータセンター用のAI処理に秀でたコアGPUで、より大規模な学習データのトレーニングにも対応しています。
NVIDIA V100
環境の構築にはNGCのコンテナをダウンロード
まずは、「Jetson Orin」側でTAO toolkit用のtarボールをダウンロードします。
展開した後、パスを張り「jupyter notebook」を呼び出します。
「jupyter notebook」はブラウザ上で動かせる統合開発環境です。対話型でステップバイステップで実行部分を区切れたりするため教育用にも使えたりします。
「Jetson AI Certification」でもそうでしたが、NVIDIAは「jupyter notbook」を使うことが多いので慣れておいた方が良いでしょう。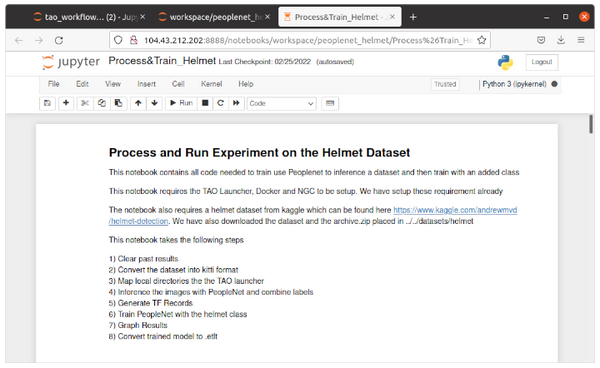
Jupyter notebookを起動すると、ブラウザが自動起動され、コンテンツの画面が表示されます。
今回は、Peoplenetという人物と顔の画像検知を行う学習モデルに、ヘルメットの検知を転移学習させるトレーニングをAzure上で行います。
トレーニングは以下のステップで行います。
1)過去の結果の消去
2)データセットをkittiフォーマットに変換
3)ローカルディレクトリをTAOラウンチャーにマップ
4)PeopleNetで画像を推論し、ラベルを組み合わせる
5)TF Recordsの生成
6)helmet(ヘルメット)クラスでPeopleNetをトレーニング
7)グラフ表示
8)トレーニング済モデルを.etltに変換
Azure VMにログインする際のステップ
NVIDIAに用意してもらったVMにログインする際には、AzureのCLIを使ってユーザ名、パスワードで認証をする必要があります。その後、VMを起動して、SSHでリモートログインを行います。
今回はNVIDIAから提供されたメールアドレス(ユーザ名)、パスワード、リソースグループ名、VMホスト名、VMユーザ名、VMパスワード、VMホストIPアドレスを使用しました。
まず最初にAzureにサインインします。jupyter-notebookのステップに従い、$sudo azure-cli-env/bin/az login -use-device-code
を実行すると、初回の場合はブラウザでAzureの認証が行われローカルに認証情報が保存されます。
次にVMを起動します。コマンドラインから、$sudo azure-cli-env/bin az vm start -g "リソースグループ名" -n "VMホスト名"
を実行すると指定されたリソースグループのVMホストが起動されます。
VMが実行されたらSSHを使ってログインします。同じくコマンドラインから、$ssh "VMユーザ名"@"VMホストIPアドレス"
でパスワードを聞かれるのでVMパスワードを入力すればログインできます。
Azure上での転移学習、Peoplenetにヘルメットの検知を追加
Azure上のVMにSSHログインした後は、VM上からjupyter notebookを起動して、ブラウザからVM上のjupyter notebookのコンテンツに従い上記の1)から7)のステップを実行します。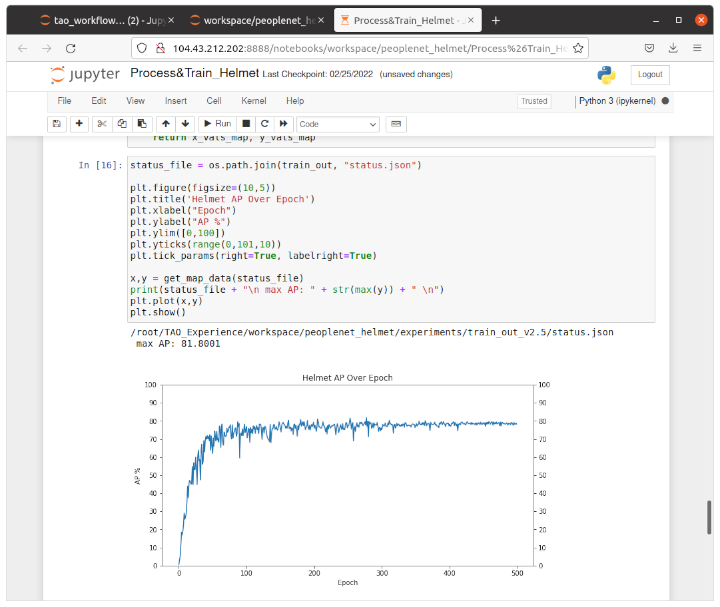
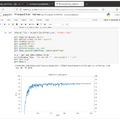
私が行った際に引っかかったのは、「7)グラフ表示」のステップでグラフが表示される前に、「8)トレーニング済モデルを.etltに変換」ステップに進んでしまい.etltが生成されないというものでした。
これはjupyter notebookの制約だと思うのですが、ステップ実行させても完了するまで待つことができず、処理が終わったか終わっていないかわからずに次に進めてしまうのはどうかと思いました。
転移学習のトレーニングをしてグラフ表示するのに体感5~10分程度かかるのでグラフが表示されるまで待ちましょう。
NVIDIA V100付きのAzureVMで動かしているので、論理性能で「Jetson Orin」の3倍、「Jetson AGX Xavier」との比較であれば10倍程度のトレーニング速度は出ているはずです。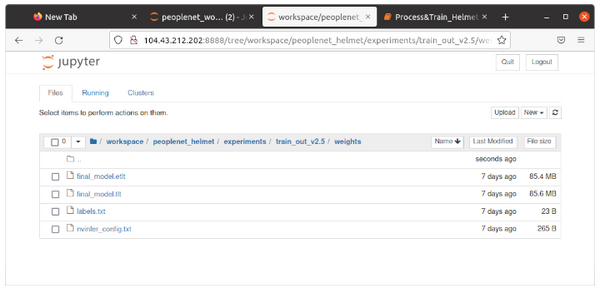
グラフの表示が終わってから「8)トレーニング済モデルを.etltに変換」ステップを実行すると、”final_model.etlt”が生成されるので、ローカルにダウンロードして指定のフォルダにセットしてください。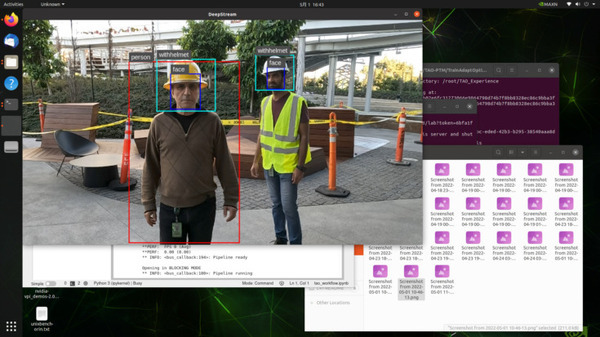
成功していれば、”person”、”face”の枠とともに”withhelmet”の枠が動画上にオーバーレイ表示されていると思います。
このようにTAO Toolkitを使うと、時間のかかるトレーニング部分をクラウドなどで効率よく処理分散できるので、時間を短縮することができます。また、短縮した時間の分、回数を回すことで精度を上げることが可能になります。
まとめ
今回は「Jetson Orin」のベンチマークと「TAO toolkit」を使った転移学習の体験レポートをお届けしました。
ベンチマークでは「Jetson Orin」の高速性能とパワーアップ、TAOの転移学習ではクラウドを組み合わせて使うことでの高速化・効率化が実感できました。実ビジネスでのAIエッジデバイスの利用イメージも膨らみます。
TAOの転移学習については今回はヘルメットクラスの追加でしたが、各々ビジネスで検出したい物体の画像とラベルを用意して適時入れ替えれば同じ手順でオリジナルの転移学習が可能になると思いますのでぜひ挑戦してみてください。
私も「Jetson Orin」はまだまだポテンシャルを秘めていると感じているのでいろいろと試してみたいと思います。