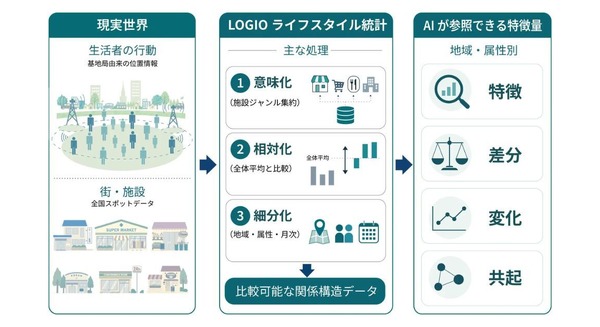
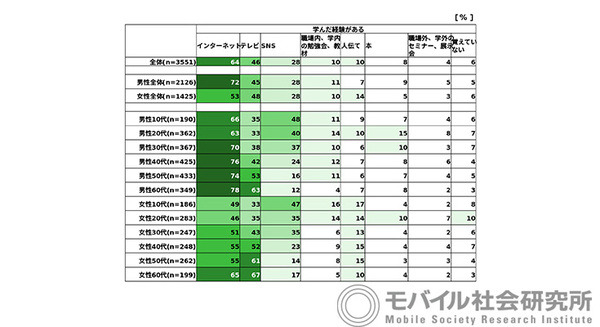
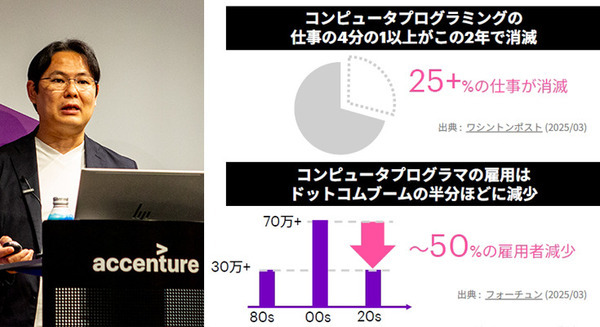
「NVIDIA 生成 AI Day 2023 Summer」で、Stability AI Japan株式会社のJerry Chi氏が登壇し、「Stable Diffusionの活用法と事例」の講演を行った。主に画像生成AI「Stable Diffusion」の機能紹介やビジネス活用の解説や動画デモだったが、その内容は「画像生成AIはこんなことまでできるようになったのか」と、全編が驚きの連続だった。

「Stable Diffusion」は画像生成AIブームを巻き起こすきっかけになったアプリケーション(ソリューション)で、最大の特徴は、絵やイラストを描いたり描画すること。写真のようなフォトリアリスティックやアニメ風に生成することもできる。
Stability AI Japan株式会社は日本支社として、研究開発やコミュニティ活動、ビジネス活動に注力している。ただし、海外のモデルを日本でそのまま使うのではなく、日本向けのモデル、日本語の言語モデルと日本語の入力ができる画像生成モデルなどの独自開発を行っている。
「Stable Diffusion」は画像生成AIの先がけであり、進化も著しく、最新版の「Stable Diffusion XL」は、従来の3倍にあたる24億パラメーターを学習し、表現力が豊かになり、複雑なプロンプトを減らし、簡単な表現でもユーザーが望むアウトプットが実現しやすくなった。更にはフォトリアリスティックな表現も生成できるようになった。
また、人間の指や手の表現が苦手で不自然に描画される、という欠点があったが、その点も大きく改善されている。
画像生成AIの驚異的な機能
Chi氏は「Stable Diffusion」に関する様々な機能や実績を紹介し、それらは既知の機能も含めてとても驚くべき内容が多かった。
Uncrop
Clipdropで使用できる機能は、範囲を拡張したときに自動に画像を埋める機能。この機能にプロンプト(文字入力)を書かなくても、範囲を拡大するだけで自動で生成される。
■Clipdrop launches Uncrop
Reimagine XL
ベースの画像を含めて、同じスタイルや要素の画像を生成する機能。ベースのような画像が欲しいけれど、少し違うアングルや別のものも見てみたいという時に有効だ。
■Clipdrop launches Reimagine XL
様々な手法で出力画像をコントロール・編集
「Stable Diffusion」を拡張する機能もあり、例えば、画像を少し手直ししたいときに、話すような自然言語で画像を編集することができる。下記の例では左は「エッフェル塔の背景に花火を追加してください」と指示して生成された画像、右は「悲しい表情にして」「アニメ風にして」とテキストで指示して編集したもの。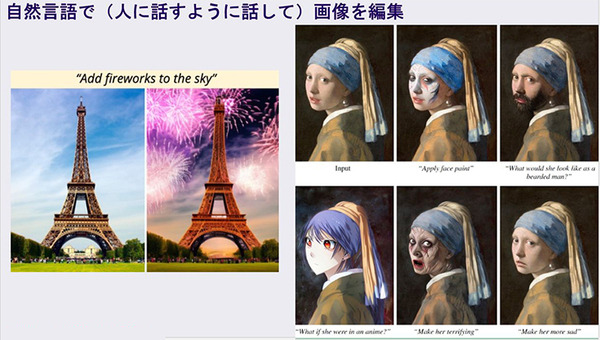
逆にテキストで指示するのはニュアンスが難しい場合、ポンチ絵のような線画でも指示して編集することができる。
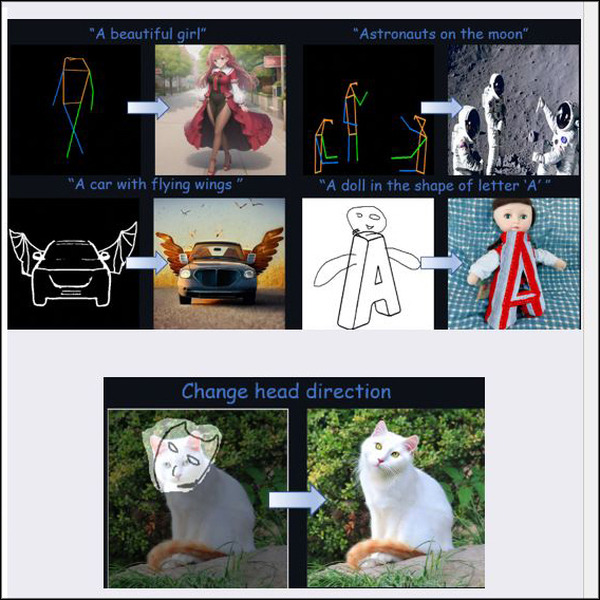
■Clipdrop Launches Stable Doodle
クリエイティブやプロモーションに活用例
Chi氏は「例えば広告のクリエイティブやプロモーション動画を「Stable Diffusion」を活かして作りやすくなりました」と語り、KDDI + WPPの「αU(アルファユー)」のプロモーション動画を紹介した。これはgeometry ogilvy japanが制作し、Stable DiffusionだけでなくMidjourneyも活用されているという。
■αU 「もう、ひとつの世界。」
メタバースに関連した動画のため、故意にAIの雰囲気を出して生成画像らしさを残しているという。
アニメーション制作の活用例
人間の動画からアニメーションを生成する技術も紹介した。
■VFX Reveal Before & After – Anime Rock, Paper, Scissors
また、Netflixのアニメ「犬と少年」では背景だけをAIが生成しているという。
■アニメ・クリエイターズ・ベース アニメ「犬と少年」本編映像 – Netflix
また、Stable Diffusionを拡張する手法「AnimateDiff」も最近は利用者が増えているという。ひとつのイメージ画像から手軽にアニメーションが作成できる。(関連リンク(リンク先で各画像をクリックすると動く):AnimateDiff)
プロダクトデザイン
次にプロダクトデザインでの活用例として、自動運転EV開発のTuring株式会社が「Stable Diffusion」でコンセプトカーをデザインを生成し、それを元に3Dモデルを作成した事例をあげた。今後は3Dモデルまで自動生成できるようにしたい、と語った。
■Turingコンセプトカー
画像生成AIの可能性
AIの画像認識モデルの訓練や機械学習のためには多くの画像が必要となる。画像を集めるのにコストや時間がかかり、時にはプライバシーの問題になることもある。そこで考えられるのが画像生成AIが作る「シンセティックデータ」(本物でないデータ)だ。大量にシンセティックデータ画像を生成して使用することでAIモデル作成の期間を大幅に短縮できる可能性がある。
衛星画像から違法漁船を検知するAIなどのトレーニングに、既に「シンセティックデータ」で学習させた。従来はGANを使用していたが、それよりもずっと高精度で短期間でモデル作成を達成したという。
また、医療ではレントゲン写真をデータを学習ユースケースも紹介した。胸部レントゲン画像の分類AI(病気の診断)を「Stable Diffusion」の生成画像(微調整あり)で学習し、性能を5%改善したことを紹介した。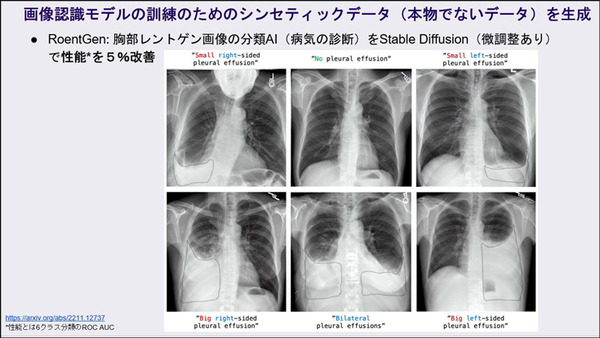
誰でもクリエイターになれる時代
Chi氏は「画像生成AIのStable Diffusionは、クリエイティブだけでなくすべての企業で活用できます。小説は書けるけれど漫画は書けない、でもマンガ家になりたかったという人が、Stable Diffusionを活用してストーリーも絵も漫画として描けるようになりました、という話も聞きました。誰でもクリエイターになれる時代が訪れます。AIと人間がどう協力させるかというプロデュースできる人、そんなスキルが重要になるかもしれません」と締めくくった。
画像生成AI「Stable Diffusion」の数々の性能に驚かれ、可能性を感じたセミナーだった。興味がある人はアーカイブを見ることをオススメしたい。(本日夜(7月28日 19時以降)よりアーカイブとして配信が行われる)