


MLPerfの業界ベンチマークでデビューを果たした「NVIDIA GH200 Grace Hopper Superchip」が、すべてのデータセンターの推論テストを実行し、NVIDIA H100 Tensorコア GPUのトップクラスの性能を証明した。
すべての結果において、クラウドからネットワークのエッジに至るまでNVIDIAのAIプラットフォームの卓越した性能と汎用性が示されている。また、NVIDIAは、同発表のほかにも、性能やエネルギー効率、総所有コストを飛躍的に向上させる推論ソフトウェアを公開した。
なお、2023年9月11日に発表された同内容は、NVIDIA JAPAN(エヌビディア合資会社)公式サイト内でも同月20日に日本語で掲載されている。
「NVIDIA GH200 Grace Hopper Superchip」
NVIDIA GH200 Grace Hopper Superchip は、巨大規模のAIおよび ハイ パフォーマンス コンピューティング(HPC)アプリケーション向けにゼロから設計された画期的な高速化されたCPUだ。このスーパーチップは、テラバイト規模のデータを実行するアプリケーションに対して最大10倍高い性能を提供し、科学者や研究者が世界で最も複雑な問題に対して前例のないソリューションを実現可能にする。
MLPerf で GH200 Superchip が輝く
GH200は、Hopper GPUとGrace CPUを1つのスーパーチップで接続しており、この組み合わせは、より多くのメモリと帯域幅を提供し、パフォーマンスを最適化するために CPUとGPU間の電力を自動的にシフトする機能を備えている。これとは別に、H100 GPUを8基搭載するNVIDIA HGX H100システムは、今回のMLPerf推論テストのすべてで最高のスループットを達成した。Grace Hopper Superchipと H100 GPUは、レコメンダーシステムや生成 AIで使用される大規模言語モデル(LLM)など、より要求の厳しいユースケースに加え、コンピューター ビジョン、音声認識、医用画像における推論など、MLPerf のすべてのデータセンターテストでリードしている。この結果は、2018年のMLPerfベンチマークの開始以来、すべてのラウンドでAIのトレーニングと推論の性能において、リーダーシップを実証してきた NVIDIAの記録を継続するものであり、最新のMLPerfのラウンドでは、レコメンダーシステムのテストが更新されたほか、AIモデルの大まかな大きさの指標である60億個のパラメータを持つLLM、「GPT-J」に関する初の推論ベンチマークが追加されている。
TensorRT-LLM が H100 GPU を強化
あらゆる規模の複雑なワークロードを処理するために、NVIDIAは推論を最適化する生成AIソフトウェアであるTensorRT-LLMを開発。同オープンソースライブラリは、8月のMLPerf提出には間に合わなかったものの、顧客は追加コストなしでH100 GPUの推論性能を2倍以上に向上できるようになるとのことだ。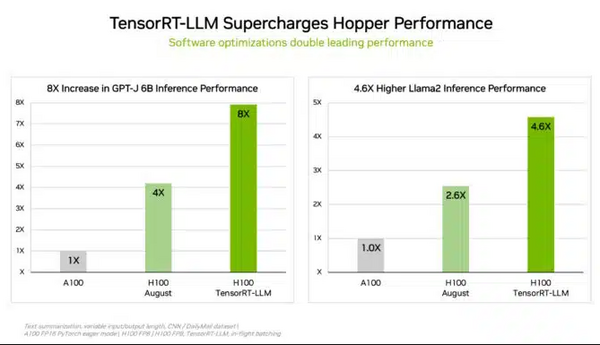
同ソフトウェアは、NVIDIA が Meta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML (現在は Databricks の一部)、OctoML、Tabnine、Together AI などの主要な企業とともにLLMの推論の高速化と最適化に取り組んだことから始まり、NVIDIAの内部テストによると、H100 GPUでTensorRT-LLMを使用した場合、このソフトウェアなしでGPT-J 6Bを前世代のGPUで実行した場合と比較すると、最大8倍の性能の高速化を実現している。また、MosaicML は TensorRT-LLM に必要な機能を追加し、既存のサービング スタックに統合。Databricksのエンジニアリング担当バイス プレジデント、Naveen Rao氏は次のように述べている。
Databricks エンジニアリング担当バイスプレジデント Naveen Rao氏
TensorRT-LLM は機能満載であり、効率的で使いやすいです。また、NVIDIA GPU を使用した LLM サービングに最先端の性能を提供し、これにより削減されたコストを顧客に還元することができます
TensorRT-LLM は、NVIDIA のフルスタックAIプラットフォームにおける継続的なイノベーションの最新の例であり、このような継続的なソフトウェアの進歩により、ユーザーは、今日の多様なAIワークロードにわたって汎用性があり、追加コストなしで時間とともに向上するパフォーマンスを得ることができる。
L4がメインストリームサーバーでの推論を強化
最新のMLPerfベンチマークで、NVIDIA L4 GPUはあらゆるワークロードを実行し、全体的に素晴らしいパフォーマンスを発揮した。例えば、コンパクトな72WのPCIeアクセラレータであるL4 GPUは、5倍近く定格消費電力の高いCPUと比べて最大6倍の性能を発揮した。さらに、L4 GPUには専用のメディア エンジンが搭載されており、CUDAソフトウェアと組み合わせることで、NVIDIA のテストではコンピューター ビジョンが最大120倍高速化された。なお、L4 GPUはGoogle Cloudや、多くのシステムビルダーから入手可能で、消費者向けインターネット サービスから創薬まで、さまざまな業界の顧客に活用されている。
エッジでのパフォーマンス向上
これとは別に、NVIDIA は新しいモデル圧縮技術を適用することで、L4 GPU上のBERT LLMの実行において最大4.7倍の性能向上を実証。この結果は、MLPerfのいわゆるオープン部門(新機能を紹介するための部門)で発表された。同技術は、あらゆるAIワークロードで利用されることが期待され、特に、サイズや消費電力に制約のあるエッジデバイス上でモデルを実行する場合に、その価値が発揮されることが期待される。また、エッジ コンピューティングにおけるリーダーシップのもう一つの例として、NVIDIA Jetson Orin システム オン モジュールは、エッジ AIやロボティクスのシナリオにおける一般的なコンピュータービジョンのユースケースである物体検出において、前ラウンドと比較して最大84%の性能向上を示した。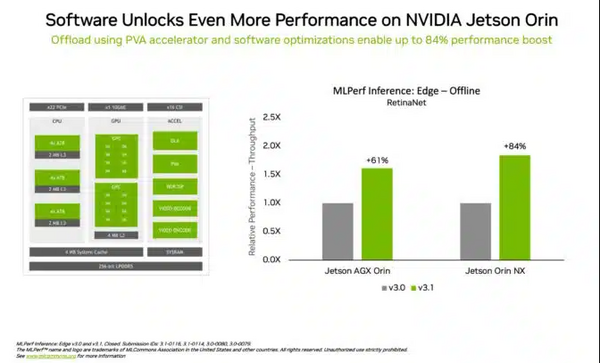
なお、Jetson Orin の進化は、プログラマブル ビジョン アクセラレータ、NVIDIA Ampere アーキテクチャ GPU、専用のディープラーニングアクセラレータなどの最新バージョンのチップのコアを活用したソフトウェアによるものとなっている。
多彩なパフォーマンス、幅広いエコシステム
MLPerf ベンチマークは透明性が高く客観的であるため、ユーザーはその結果を信頼し、十分な情報に基づいた購入決定を行うことが可能。また、幅広い使用ケースやシナリオを網羅しているため、ユーザーは信頼性と柔軟性を兼ね備えたパフォーマンスを得ることができる。また、NVIDIA のベンチマークで使用されているソフトウェアはすべてMLPerfのリポジトリから入手できるため、誰もが同様の世界レベルの結果を得ることが可能。NVIDIAはこれらの最適化を、GPUアプリケーション用のNVIDIA NGCソフトウェアハブで利用可能なコンテナに継続的に組み込んでいる。今回のラウンドに参加したパートナーには、クラウド サービス プロバイダーとしては Microsoft Azure とOracle Cloud Infrastructure、システム メーカーとしては ASUS、Connect Tech、Dell Technologies、富士通、GIGABYTE、Hewlett Packard Enterprise、Lenovo、QCT、Supermicro が含まれており、MLPerfは全体として、Alibaba、Arm、Cisco、Google、ハーバード大学、Intel、Meta、Microsoft、トロント大学など 70 以上の組織から支援を受けている。
なお、これらの最新の結果の達成については技術ブログ内「NVIDIA TensorRT-LLM が NVIDIA H100 GPU 上で大規模言語モデル推論をさらに強化」にて詳細を確認できる。
https://www.nvidia.com/ja-jp/data-center/grace-hopper-superchip/
H100 Tensor コア GPU:
https://www.nvidia.com/ja-jp/data-center/h100/
NVIDIA関連記事(ロボスタ)
NVIDIA



