


日本電信電話株式会社(NTT)とNTTデータ数理システムは、複数のクライアント(個人や組織)でデータを保持したまま分散して学習する連合学習において、一部のクライアントに異常や悪意がある場合にも高精度にAIモデルを学習可能な学習手法を開発した。
連合学習において一部のクライアントに異常や悪意がある場合にも高精度にAIモデルを学習可能な「連合学習技術(モメンタムスクリーニング技術)」を開発、それが数理的・実験的に従来手法に対する有効性を確認したこと、これらが機械学習分野における最難関の国際会議「ICLR2024」に採択されたことを発表した。
NTTは事前に報道関係者向け発表会を開催して、内容の詳細を解説した。
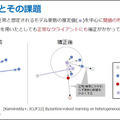
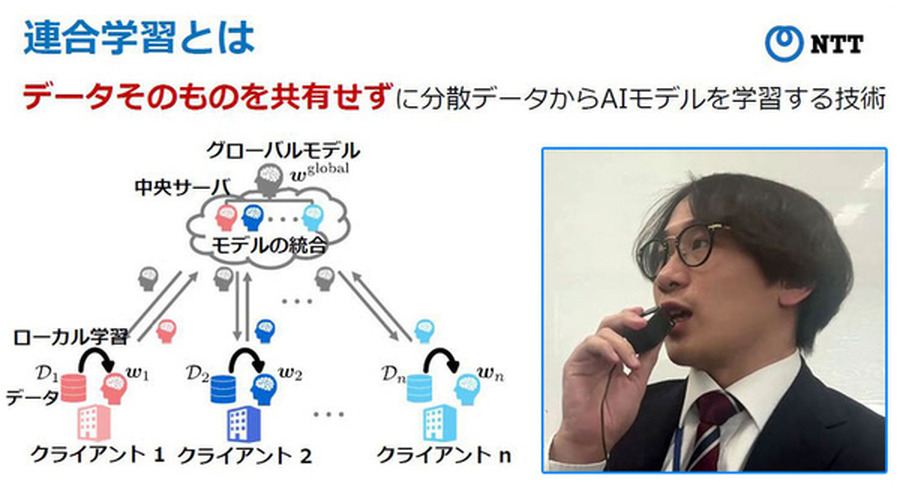
「連合学習」とは、複数の組織で保持しているデータを一か所に集約せずに、組織横断のAIモデルを学習させることを可能にする技術(2017年にGoogleが提唱した技術)。プライバシーなど機微な情報が含まれるようなデータは、組織の外に持ち出すことが難しいが、データを持ち出さずに組織ごとに生成したAIモデルを合わせる「連合学習」は解決策の一つとして注目されている。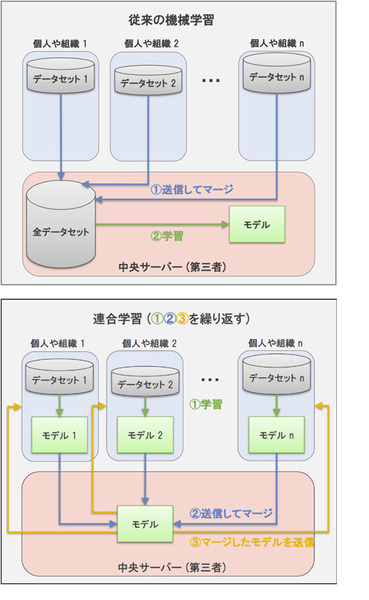
AI「連合学習」とは
目覚ましいAIの発展とともに、すぐれたAIモデルを生成するため、大量のデータを集めることが必要とされている。その点において、高精度なAIモデルを生成するには複数の組織を横断してデータを一ヶ所に集積し、それを元に学習してAIモデルを生成することが理想的だ。しかし、一方で機微なデータの共有はプライバシーや機密の情報などが含まれることが多いため困難であり、それらを用いたモデルの構築は十分に進んでいない現状が課題だった。
「連合学習」ではデータを持ち出したり、ひとつの場所に集積することなく、各組織ごとに生成した「AIモデル」を合わせる手法のため、この課題を乗り越える技術して注目されている。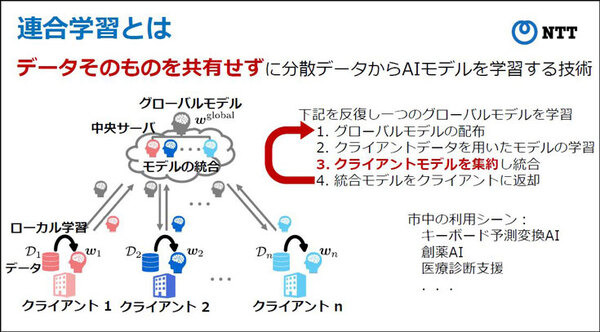
例えば、医療施設、教育機関、企業など、高精度なAIモデルを生成して活用するためには、複数の病院、複数の学校、複数の同業他社が収集したデータからそれぞれの組織が作成したAIモデルを合わせることで、同分野においてより高精度なAIモデルを創ることができる。これはAI「連合学習」と呼ばれ、実データの共有や外部への持ち出しを回避することができる。
すなわち、連合学習技術はデータの共有はせずに、データから学習されたAIモデルを複数組織で共有/集約することで、各組織が持つデータの特徴を活かしたモデルを生成でき、データを保護しながら「組織を横断して高精度なAIモデル」を生成する技術といえる。
低レベルや悪意のあるAIモデルが連合学習に参加した場合の懸念
そして、連合学習技術が次に抱える課題は、参加する組織の一部が、非常に精度が悪いAIモデルや、悪意を持って作成された異常なAIモデルを提出し共有した際、それを学習モデルのひとつとして「連合学習」に加えた場合、精度が低下する可能性が懸念されることとなる。これらのマイナス要因をビザンチン障害性と呼び、それらの耐性となるビザンチン障害耐性が連合学習には求められている。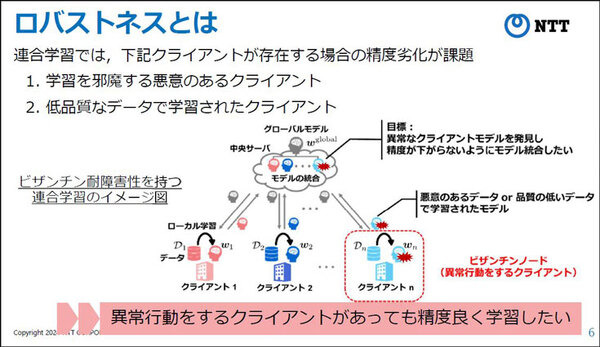
外要因による堅牢性という意味では「ロバストネス」(ロバスト性)と表現される場合もある。
また、非常に精度が悪いAIモデルや、悪意を持って作成された異常なAIモデルを除外すれば対策となるが、安易に除外することで正常なモデルも除外してしまうと、やはり連合学習のモデルの精度を落とすことになってしまう。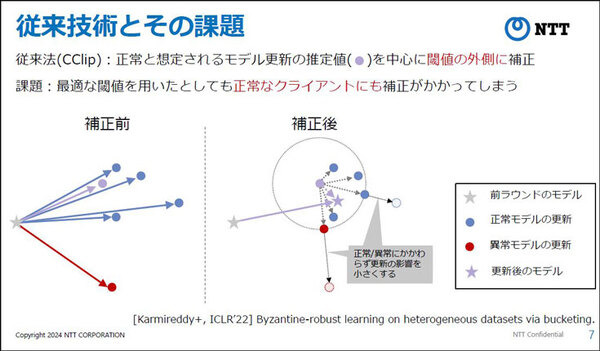
ビザンチン耐障害性を持った連合学習技術を開発
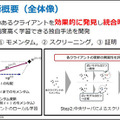
今回、NTTが開発・発表した連合学習手法は、異常あるいは悪意のあるクライアント(組織)がいる場合でも、連合学習自体の精度は極力落とすことなく、ビザンチン耐障害性があると言われる手法。モメンタムとスクリーニング手法を用いるもので、その有用性を証明することにも成功した。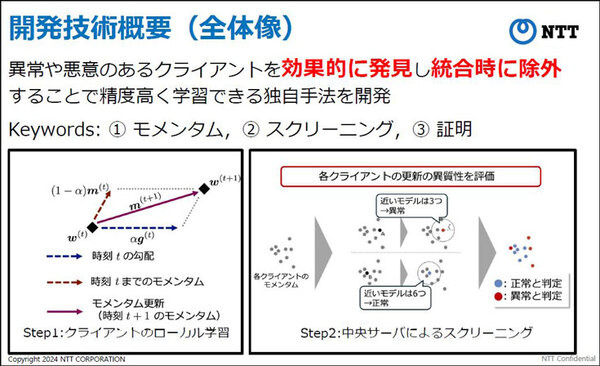
モメンタム
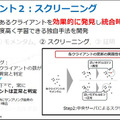
異常や悪意のあるクライアントを効果的に発見し、統合時に除外することで精度を落とさずに学習できる独自のモメンタム手法を開発した。過去の勾配を考慮したモデル更新を行うことで、学習時における確率的なノイズの影響を低減するとともに、正常なクライアントが誤って除外されることを抑えるもの。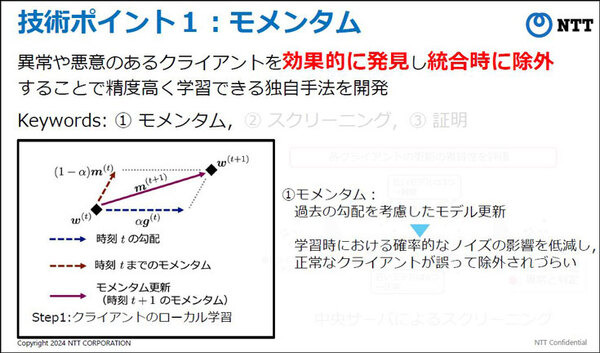
スクリーニング
サンプリング由来の確率的なノイズがない理想的な条件下で、常に正常なクライアントは正常と判定することを高精度で実現した。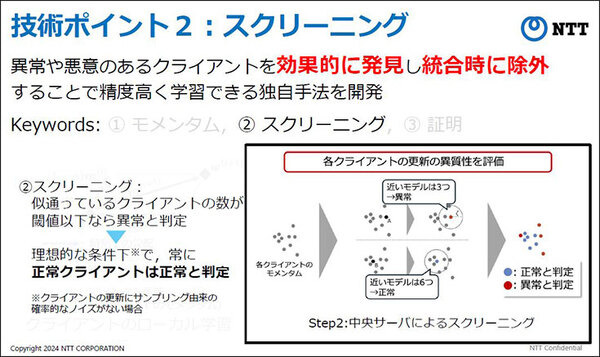
証明
NTTは、これらの手法を用いることで、従来手法よりも精度の高いモデルを生成できることを実験的に確認し、数理的な解析によってクライアント(共有する組織)間でのデータの一般的な統計的偏りを想定した目的関数において、提案手法を上回る手法が存在しないことを証明した。
この技術は機械学習分野の三大トップカンファレンスのひとつ「International Conference on Learning Representation 2024」 (ICLR2024:5月7日~11日)に採択され、オーストリア・ウィーンで発表する。
今後の展望
NTTは、組織横断的に分散蓄積されるデータを用いたAI等の利活用の促進に貢献するとともに、NTTが推進するIOWN PETs機能として実用化することを目指す。また、将来的にはNTT版LLM(大規模言語モデル)「Tsuzumi」の学習への適用も検討できる、としている。IOWN PETs機能のPETsとは、Privacy Enhancing Technologiesの略称で、プライバシーを保護したままデータを処理する技術の総称。NTTはPETsを発展させ、IOWNのひとつの機能として、蓄積・伝送時のみでなく、計算空間も含めたエンド・ツー・エンドでデータのガバナンスを保つ研究をおこなっている。
NTT【世界初】AIモデルの再学習に有効な「学習転移」を発表 「tsuzumi」など大規模基盤モデルの更新時に過去の学習過程を再利用
NTTが大規模言語モデルに文書を視覚情報から理解する「視覚読解技術」を確立 NTT版LLM 生成AI「tsuzumi」に採用
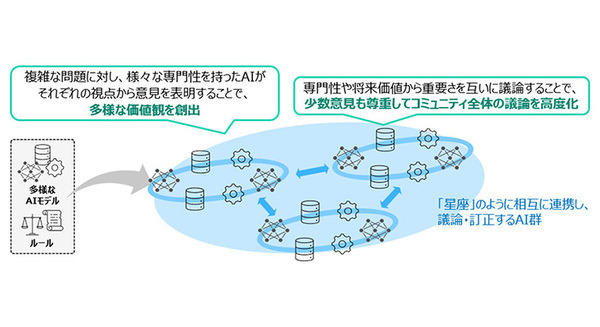
NTTとSakana AIが「AIコンステレーション研究」で連携 大規模言語モデルと小型で賢いAIを連携、複雑な社会課題の解決をめざす
【速報】NTT版 大規模言語モデル(LLM)「tsuzumi」(つづみ)の商用サービスを開始 2027年に1千億円の売上を目指す
NTT版生成AI大規模言語モデル(LLM)「tsuzumi」驚異の性能を披露 NTT R&Dフォーラム2023開幕 NTT島田社長の基調講演と見どころ
NTT tuzumi関連記事