






NVIDIAが開発している対話型AIシステムが「Jarvis」(ジャービス)だ。以前から開発についてはアナウンスされていたが、ついに正式にリリースされた。しかも日本語対応で。
「GTC 2021」のオンライン基調講演でNVIDIAのCEO、ジェンスン フアン氏(Jensen Huang)がこのニュースを紹介するとともに、聞き取り、発話、翻訳などのデモを行った。「Jarvis」はHuang氏が話した言葉を瞬時にテキスト化し、更にはHuang氏が話した英語を日本語にリアルタイム翻訳して見せた。
対話型AIフレームワーク「NVIDIA Jarvis」
NVIDIAは現地時間の4月12日、「NVIDIA Jarvis フレームワーク」の提供を開始したことを発表した。これは最先端のAIトレーニング済みディープラーニング モデルとソフトウェア ツールを活用して、さまざまな業界と分野向けに、対話型AIサービスを簡単に構築できるようになることを意味する。
英語、日本語、スペイン語、フランス語、ロシア語の5言語に対応している。
リリースを通じてNVIDIAは「私たちの生活では、数十億時間分もの電話通話、Web ミーティング、ストリーミング配信による動画コンテンツが毎日生み出されています。こうした中 NVIDIA Jarvisは、高精度な自動音声認識、人間の能力を超えた言語理解、複数言語へのリアルタイム翻訳、新しいテキスト読み上げ機能を提供し、表現力に優れた対話型 AI エージェントの開発を可能にします」とコメントしている。
Jarvisは、GPUアクセラレーションを活用したエンドツーエンドの音声パイプラインを持つ。その速度は高速で、100ミリ秒未満で、聴き取り、理解、応答の生成が実行可能となっている。Huang氏いわく「人間のまばたきよりも速く処理する。音声パイプラインはクラウド、データ センター、エッジに展開し、瞬時にスケーリングして数百万ユーザーに対応できる。Jetsonに組み込んだロボットやエッジにもデプロイできる。対話型AIは、多くの点で究極のAIと言えるだろう」。
Jarvisは、人間やマシン(機械/コンピュータ)との間に質の高いインタラクションを提供し、これまで実現できなかった新しい言語ベース・アプリケーションを可能にするという。例えば、24時間、患者をモニタリングすることで医療従事者の厳しい負担を和らげるデジタル・ナース、消費者が求めている商品を理解して最適な候補を提案するオンライン・アシスタント、国境を越えた質の高い共同作業や母国語でのライブ・コンテンツ視聴を可能にするリアルタイム翻訳など、さまざまなサービスの可能性が開かれる、としている。
Jarvisは、異なる言語、発音、環境、専門用語で構成された10億ページ以上のテキストおよび60,000時間分の音声データで、数百万GPU時間をかけてトレーニングされたさまざまなモデルを使って構築されている。開発者は「NVIDIA TAO」と呼ばれるフレームワークを使ってトレーニング、適応、最適化することにより、タスクや業界に特化したり、分野別システムにモデルを簡単に対応させることも初めて可能になった。
しかも開発には、AIの高度な専門知識は必要ない、と付け加えている。
発話に関しては感情や抑揚を制御することもできる。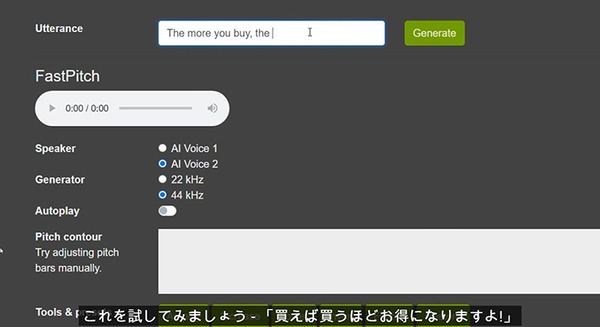
また、デモではHuang氏が英語を話して「Jarvis」が即座に日本語に翻訳するデモも実施している。その翻訳の内容が「有名なジャンガララーメン店を探しています」「とてもお腹がすいています」。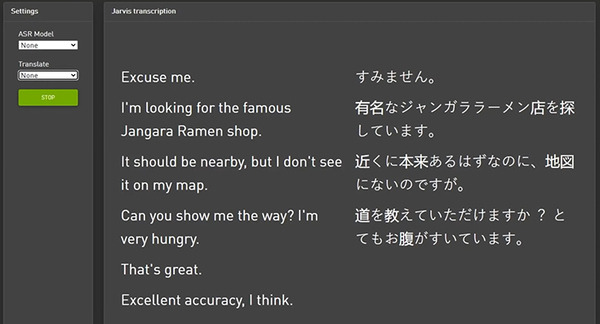
これらの様子はすべて基調講演の動画でチェックできる(字幕と言語の指定で日本語表示可能)。6分50秒あたりから。
T-MobileやMozillaのコメント
基調講演では、米国の大手通信企業「T-Mobile」が早期導入ユーザーとして参加したことを紹介。AIに注目している T-Mobile では、同社の機械学習製品を自然言語処理によって強化し、リアルタイムにインサイトやレコメンデーションを提供しようとしているという。
T-Mobileの製品およびテクノロジ担当バイス プレジデントであるマシュー・デイビス氏 (Matthew Davis) 氏は次のようにコメントを寄せている。
Matthew Davis氏
T-Mobile のデータでファインチューニングした NVIDIA Jarvis サービスを使い、お客様の問題をリアルタイムで解決する製品を開発中です。自動音声認識ソリューションをいくつか評価した結果、Jarvis にたどり着きました。驚異的な低レイテンシで高品質なモデルを提供してくれる Jarvis があれば、お客様を喜ばせる体験を実現できます
さらに NVIDIA は、音声対応のアプリ、サービス、デバイスのトレーニングに使えるオープン・ソースの音声データ・コレクションをスタートアップ企業、研究者、開発者向けに提供している「Mozilla Common Voice」とも連携。60種類の言語、9,000時間分にも及ぶ無償提供の音声データを擁する「Common Voice」は、パブリック・ドメインの音声データセットとしては世界最大規模を誇る。NVIDIAは、これらのデータセットと「Jarvis」を使用してトレーニング済みモデルを開発し、そのモデルを「Mozilla コミュニティ」に無償で還元しているとしている。
Mozilla のエグゼクティブ ディレクターを務めるマーク サーマン (Mark Surman) 氏は次のようにコメントを寄せた。
Mark Surman氏
Mozilla が立ち上げた Common Voice を通して、現実の人間がそれぞれの言語、アクセント、言葉遣いでどのように喋っているかをマシンに教え込むことができます。NVIDIA と Mozilla には、音声技術を誰もが使えるようなテクノロジにし、インターネットを形作っている人間とその声の多様さを音声技術にも反映させる、という共通のビジョンがあります
基調講演でHuang氏は「NVIDIA の対話型 AIツールはこれまで45,000回以上ダウンロードされている。これらのツールは主要なソフトウェア ライブラリに対応しており、数多くのパートナーによるテクノロジと組み合わせることができるため、世界中の開発者が革新的で直感的な対話型 AI アプリケーションを生み出すことができる」と語った。
NVIDIAが1枚の写真からナイトライダー「ナイト2000」の3Dモデルを生成、疾走する動画を公開 GANと「Omniverse」を活用
NVIDIAとBMWが作る「デジタルツイン」の自動車工場を紹介 人と協働ロボットの計画プロセスを30%効率化【GTC 2021】
NVIDIAとアストラゼネカが協業 創薬におけるAIの活用を支援 有望な新薬のいち早い発見のため必要なツールを研究者に提供
ソフトバンクが「NVIDIA Maxine」とMECで5G通信の映像を「超解像」化する実験に成功 ウェブ会議の画質を向上する技術
NVIDIAがデータセンター向けCPUに本格参入へ ArmベースのCPU「Grace」発表 並列GPUで「x86」の10倍高速化できる理由
NVIDIAが5GとAIエッジ「AI-on-5G」や自動運転車向け最新「NVIDIA DRIVE Atlan」、連携企業などを発表【GTC2021】
「GTC 2021」関連記事 (ロボスタ)















