






NVIDIAは「NVIDIA H100 Tensor コア GPU」(別名Hopper)が、業界標準のAIベンチマーク「MLPerf」でデビューし、すべてのワークロードの推論で世界記録を樹立し、前世代GPUより最大4.5倍のパフォーマンスを実現したことを発表した。
また、NVIDIA A100 TensorコアGPUとAI搭載ロボティクス用のNVIDIA Jetson AGX OrinモジュールはすべてのMLPerfテスト(画像と音声認識、自然言語処理、レコメンダー システム)で他をリードする推論パフォーマンスを引き続き実現した。
データセンターカテゴリのすべてのワークロードで新たな最高水準を記録
NVIDIA H100 GPUは第4世代のTensorコアとFP8精度のTransformer Engineを搭載し、MoE(Mixture-of-Experts)モデルのトレーニングを前世代よりも最大9倍高速化する。900ギガバイト/秒(GB/s)のGPU間インターコネクトを提供する第4世代のNVlink、ノード間の各GPUによる通信を加速するNVLINK Switchシステム、PCIe Gen5、およびNVIDIA Magnum IOソフトウェアの組み合わせによって、小規模な企業から大規模で統一されたGPUクラスターまで効率的に拡張できるようになっている。
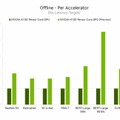
H100、別名Hopperは今回のラウンドの6つのニューラルネットワークすべてでアクセラレータあたりのパフォーマンスの基準を引き上げた。また、個別のサーバーシナリオおよびオフラインシナリオで、スループットと速度の両方でリードしていることを示した。
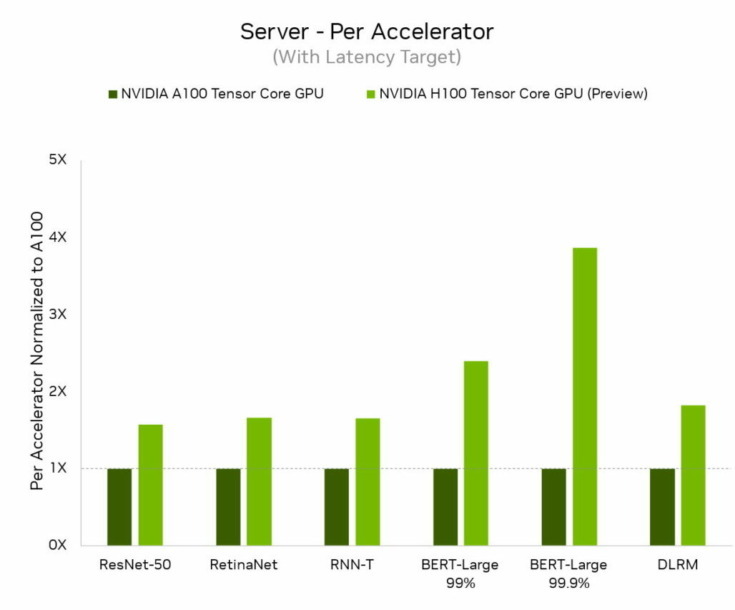
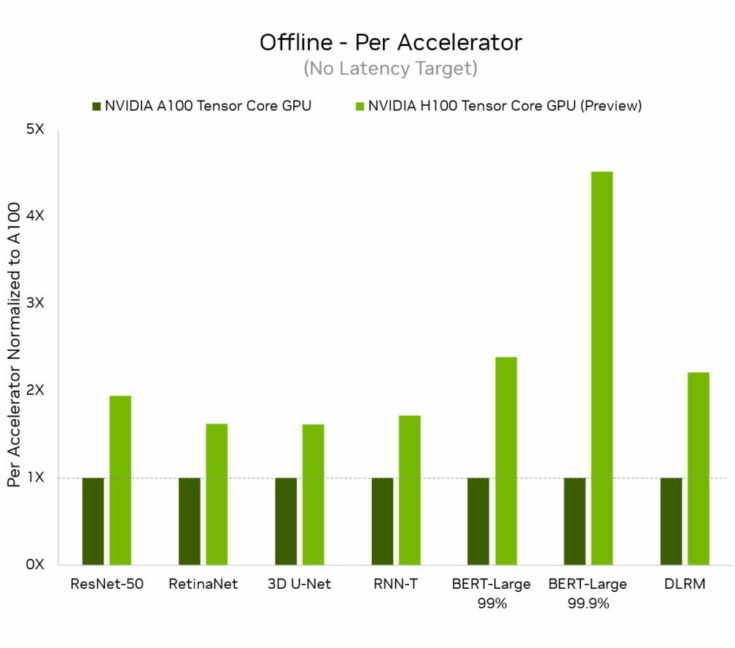
NVIDIA HopperアーキテクチャはNVIDIA AmpereアーキテクチャGPUよりも最大4.5倍のパフォーマンスを発揮し、MLPerfのすべてのテストの結果をリードし続けている。Transformer Engineの搭載により、Hopperは自然言語処理の一般的なBERTモデルにおいて特に優れていた。これはMLPerf AIモデルの中で最大かつ最もパフォーマンスを必要とするモデルの1つ。
これらの推論ベンチマークは今年後半に利用可能になるH100 GPUの性能が初めて一般公開されたデモンストレーションとなる。H100 GPUは今後のMLPerf のトレーニングのテストにも参加し、結果が提出される予定。
実際のアプリケーションでは通常、さまざまな種類の多くのニューラルネットワークが採用されている。たとえば、あるAIアプリケーションはユーザーの音声による要求を理解し、画像を分類し、レコメンデーションを行い、人間の声で音声メッセージとして応答する必要がある。各ステップには、異なるタイプのAIモデルが必要。
MLPerfのベンチマークは、これらおよびその他の一般的なAIワークロードとシナリオ(コンピューター ビジョン、自然言語処理、レコメンダー システム、音声認識など)を網羅している。これらのテストにより、ユーザーは信頼性が高く柔軟に展開できるパフォーマンスを得られることが保証される。テストは透明で客観的であるため、ユーザーはMLPerfの結果を信頼して、情報に基づいた購入決定を下すことができる。ベンチマークはAmazon、Arm、百度、Google、ハーバード大学、Intel、Meta、Microsoft、スタンフォード大学、トロント大学を含む幅広い企業や機関から支持されている。
A100 GPUがリーダーシップを発揮
主要なクラウドサービスプロバイダーおよびシステムメーカーから現在入手可能なNVIDIA A100 GPUは、最新のテストでAI推論のメインストリームパフォーマンスにおいて引き続き全体をリードした。A100 GPUはデータセンターおよびエッジコンピューティングのカテゴリとシナリオにおいて、他社製品よりも多くのテストで首位を獲得。6月のMLPerf トレーニング ベンチマークでもA100は全体をリードし、AIワークフロー全体においてその能力を実証した。2020年7月にMLPerfでデビューして以来、A100 GPUはNVIDIA AIソフトウェアの継続的な改善により、パフォーマンスを6倍向上している。
Orinがエッジでリード
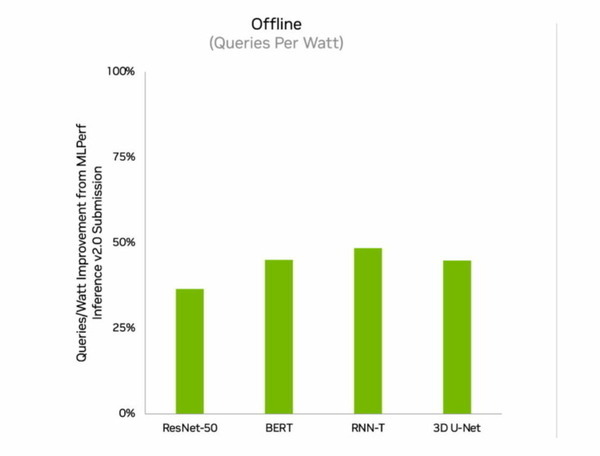
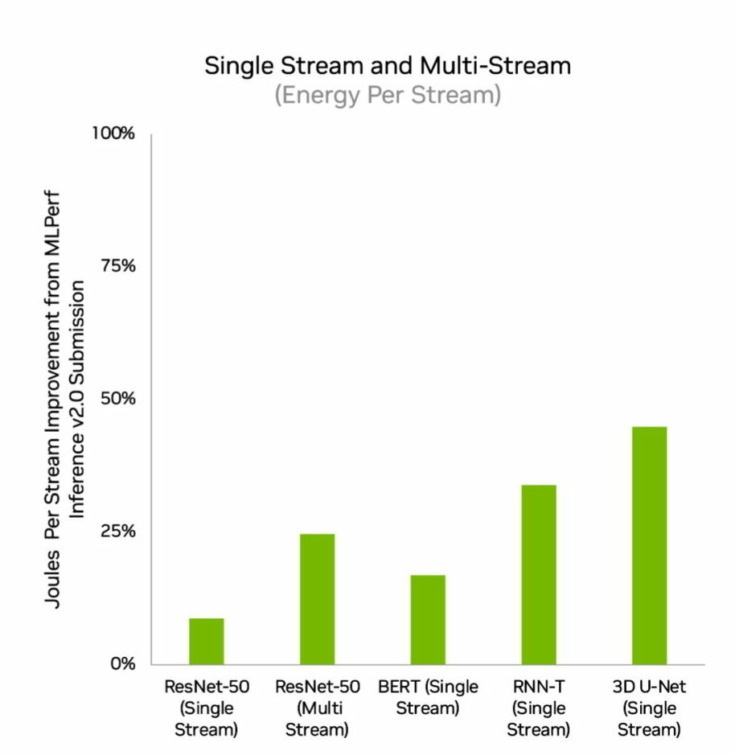
エッジコンピューティングではNVIDIA OrinがすべてのMLPerfベンチマークを実行し、他のあらゆる低電力なシステムオンチップ(SoC)よりも多くのテストでトップの結果を獲得した。また、4月にMLPerfにデビューしたときと比較して、エネルギー効率が最大50%向上した。前回のラウンドではOrinは前世代のJetson AGX Xavierモジュールよりも平均2倍のエネルギー効率と最大5倍の高速化を実現した。
OrinはNVIDIA Ampere アーキテクチャ GPUと強力なArm CPU コアのクラスターをシングルチップに統合する。現在、NVIDIA Jetson AGX Orin 開発者キットおよびロボティクスや自律システム用の生産モジュールで利用可能。自動運転 (NVIDIA Hyperion)、医療機器 (Clara Holoscan)、ロボティクス (Isaac) 向けのプラットフォームを含む完全なNVIDIA AIソフトウェアスタックをサポートしている。
広範なNVIDIA AIエコシステム
MLPerfの結果はNVIDIA AIが業界で最も広範な機械学習エコシステムに支えられていることを示している。このラウンドの70以上の提出結果がNVIDIAプラットフォーム上で実行された。例えば、Microsoft Azureは同社のクラウドサービス上でNVIDIA AIを実行したテスト結果を提出した。
さらに、ASUS、Dell Technologies、富士通、GIGABYTE、Hewlett Packard Enterprise、Lenovo、Supermicroを含む10社のシステムメーカーから19のNVIDIA-Certified Systemsがこのラウンドに参加した。これらの成果はユーザーがクラウドおよび独自のデータセンターで実行されているサーバーの両方でNVIDIA AIを使用して優れたパフォーマンスを得ることができることを示している。
NVIDIAのパートナーがMLPerfに参加する理由は、MLPerfがAIプラットフォームやベンダーを評価する顧客にとって価値のあるツールだから。最新のラウンドの結果は現在ユーザーに提供しているパフォーマンスがNVIDIAプラットフォームによって向上することを示している。
これらのテストに使用されたすべてのソフトウェアはMLPerfリポジトリから入手でき、誰でもこの世界クラスのパフォーマンスを得ることができる。NVIDIAのGPU アクセラレーテッドソフトウェアのカタログであるNGCで利用可能なコンテナーでは継続的な最適化が組み込まれている。今回、AI推論を最適化するためにすべての提出結果でNVIDIA TensorRT が使用されているが、こちらもNGCより入手することができる。
NVIDIAのMLPerfのパフォーマンスを支えているテクノロジについては、NVIDIAの技術ブログで詳しく紹介されている。
NVIDIA「GTC 2022」9月19日からオンライン開催
GPUとディープラーニングの世界最大級のイベント「GTC 2022」が9月19日から22日にオンライン開催される。既に参加申込みの受付がはじまっている。新たなAIについての発表も予定されているので、もしかしたら「QPU」に関する情報のアップデートもあるかもしれない。ディープラーニング業界をリードしてきた有識者たちによるトークセッションにも注目だ。
詳細は別途記事「世界最大級のAIイベント「NVIDIA GTC」9/19からオンライン開催、参加受付開始 基調講演で新しいAI、メタバーステクノロジを発表、著名な教授陣のトークショーにも注目」で掲載している。参加予定の方は申込みを忘れずに。
「GTC 2022」Jetson/自律マシン、AIビジョン関連で注目のセッション5選 AIとGPUの世界最大級のイベントは9月19日から
「GTC 2022」Jetson/
「GTC 2022」で日本語ワークショップ「アクセラレーテッドデータサイエンスの基礎」を開催、参加者はNVIDIA公式グッズがもらえる
「GTC 2022」NVIDIA、量子プロセッサ「QPU」に言及 「量子のしくみ、期待される役割、実用時期」等を解説、QODAベータ版は年内リリースへ
「GTC 2022」NVIDIA関連記事













