モルフォグループにおいてAIの事業化を担う、モルフォAIソリューションズは、日本語大規模言語モデル(LLM)の学習データを生成するための、AI-OCR(Optical Character Recognition:光学文字認識)出力サービスの提供を2023年12月19日より開始すると発表した。
今回提供を開始するサービスは、独自LLMの構築を検討している企業・官公庁・地方自治体等や、LLM開発を進めるAI企業・研究機関向けに正確で多様な日本語テキストデータを提供する。
LLM構築における日本語学習データの多様性の欠如
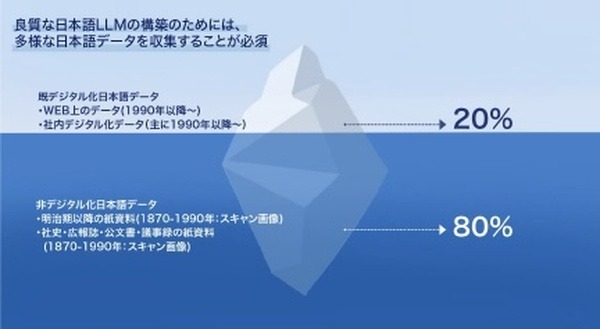
良質な日本語LLMの構築のためには、多様な日本語データを収集することが必須だが、一般的に収集可能な日本語テキストデータは主にインターネット普及後の1990年以降のものが中心となっており、1990年以前の文書(社史・広報誌・公文書・議事録等の保存文書)の多くはデジタルデータ化されておらず、効率的に収集することができていなかった。
そのため、LLM構築を進める組織の多くは、多様な日本語学習データが用意できず公開された共通のデータセットを活用せざるを得ない状況であり、結果として良質なLLMの構築に制約がかかっている。
日本語文書に対応したAI-OCRの重要性
保存文書のデジタル化のためにはOCRが必要となるが、市販OCRの多くは請求書や領収書といった「帳票向け」に開発されたもので、日本語の文書は多様なレイアウト(縦書き、横書き、多段組等)、多様な文字種が混在するため、市販のOCRでは読み順を含めた正確な日本語の抽出が難しいという課題がある。
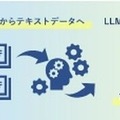
モルフォAIソリューションズの提供するOCR出力サービスは、上記の市販OCRが苦手としている文章の読み順まで含めた高精度のテキスト生成を行ることで、組織が保有するスキャン画像データから多様かつ正確な日本語を生成することで、日本語LLMの学習データの作成を支援する。
サービス内容、特徴、実績
サービス内容
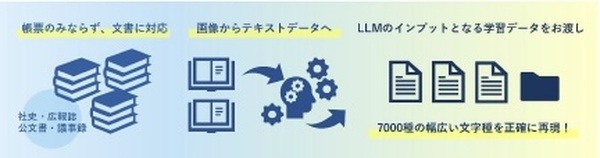
既存文書(社史・広報誌・公文書・議事録等)のデジタル化とLLM学習データへの変換
特徴
1:帳票ではなく、文書に対応したAI-OCR
・LLMに入力する際に重要な読み順まで再現
・文字種は約7000種類で、複雑な漢字も読み取り可能
2:画像(JPEG,PDF,PNG等)が含まれている雑多な文書を、テキスト(様々なフォーマット)で出力可能
実績
国立国会図書館をはじめとして、様々な機関向けにテキスト生成を実施済み
(沖縄県豊見城市/ボローニャ大学/順天堂大学/滋賀県立図書館/大手新聞社 等多数)
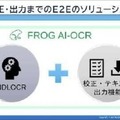
FROG AI-OCR紹介
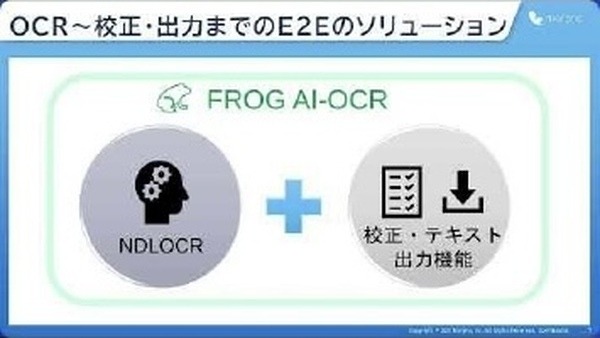
FROG AI-OCRは、手軽にOCR適用業務が行えるようNDLOCRの高精度なOCR処理に加えて、校正・テキスト出力機能も1つのパッケージとしてご提供している。
機能は全てクラウドで利用可能で、出力テキストの確認・修正作業を効率良く行うことが可能となる。FROG AI-OCRは、国立国会図書館のNDLOCR(https://github.com/ndl-lab/ndlocr_cli)をコアエンジンとして利用している。
カメラとAI画像解析でアナログ計器を自動確認 水力発電所で計器のAI読取り技術の実証 モルフォAIがデジタル庁事業に採択
モルフォ、自動車分野向けAIソリューションをパッケージ化『Morpho Automotive Suite』提供開始 モビリティ分野のAI技術を解説
モルフォ、自動車分野向けAIソリューションをパッケージ化『Morpho Automotive Suite』提供開始 モビリティ分野のAI技術を解説
滋賀県立図書館がモルフォAISの高性能OCRを導入 郷土資料のデジタルアーカイブ化、視覚障害者向け書籍テキスト化への活用目指す
株式会社モルフォAIソリューションズ