NVIDIAは、2024年3月に開催した「GTC 2024」(関連記事)にて、NVIDIA Blackwellプラットフォームを発表した(出荷時期は2025年後半を予定)。このプラットフォームは、兆単位のパラメーターを持つLLM (大規模言語モデル) による生成AIをNVIDIA Hopperアーキテクチャの最小1/25のコストとエネルギー使用量で実現する。
BlackwellはAIワークロードに強力な影響を及ぼすだけでなく、その技術的能力により、従来の数値シミュレーションを含む、あらゆる種類の科学コンピューティングアプリケーションに発見をもたらすのに貢献する、とNVIDIAは述べている。
アクセラレーテッドコンピューティングとAIは、エネルギーコストを削減することでサステナブルなコンピューティングを促進する。多くの科学コンピューティングアプリケーションには、既にその効果が出ていて、従来のCPUベースのシステムなどと比べて、気象シミュレーションを1/200のコスト、1/300 のエネルギーで行い、デジタルツインシミュレーションを1/65のコスト、1/58のエネルギー使用量で行うことが可能になっている。
アクセラレーテッド コンピューティングとAIの進化が世界の次なる大規模なブレイクスルーを牽引する中、量子コンピューティング、創薬、核融合エネルギーなど、大規模な演算能力が必要な分野において、科学コンピューティングと物理ベースのシミュレーションが大きな進展を遂げようとしている。生成AIや人型ロボットの運用や開発の効率化も期待されている。
Blackwellによる大規模シミュレーションの効率化
科学コンピューティングおよび物理ベースのシミュレーションでは、多くの場合倍精度形式またはFP64(浮動小数点)として知られるデータ形式を利用して問題を解決する。Blackwell GPUは、Hopperよりも30%高いFP64とFP32のFMA(融合積和演算)のパフォーマンスを実現する。
物理ベースのシミュレーションは、製品の設計と開発では重要な役割を果たす。飛行機や電車から、橋、シリコン チップ、医薬品に至るまで、シミュレーションで製品をテストし改善することで、研究者と開発者は、数十億ドルのコスト削減を実現している。
現在、ASIC (特定用途向け集積回路) は、主にCPUを使用して設計されており、電圧や電流を特定するアナログ分析を含む長くて複雑なワークフローを経ている。
しかし、その状況も変わってきている。Cadence SpectreXシミュレーターは、アナログ回路設計ソルバーの一例だ。SpectreX回路シミュレーションは、Blackwell GPUとGrace CPUを組み合わせたGB200 Grace Blackwell Superchipで、従来のCPUよりも13倍速く実行されると予想されている。
別の用途として、Cadence Realityのデジタルツインソフトウェアを使用して、サーバー、冷却システム、電源などのすべての構成設備を含む、物理的なデータセンターの仮想レプリカを構築できる。こうした仮想モデルにより、エンジニアは実世界に実装する前にさまざまな構成やシナリオをテストし、時間とコストを節約することができる。
Cadence Realityの「魔法」は、熱、空気の流れ、電力の使用がデータセンターにどのような影響を及ぼすかシミュレートできる物理ベースのアルゴリズムによるものだ。これにより、エンジニアやデータセンターの運営者は、キャパシティをより効果的に管理し、運用に関する潜在的な問題を予測し、情報に基づいて意思決定を行い、データセンターのレイアウトや運用を最適化することで、効率性と容量の使用効率を向上できる。Blackwell GPUを使用すると、CPUと比べてこれらのシミュレーションを最大30倍速く実行し、エネルギー効率の向上も期待できる。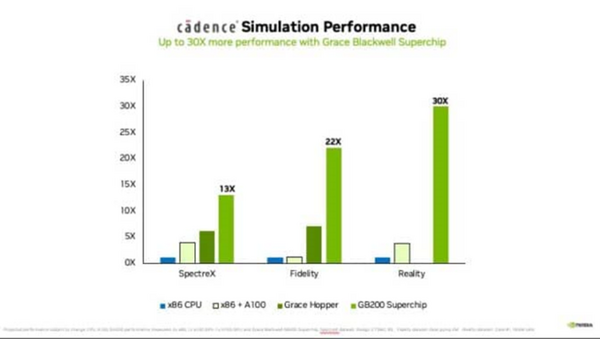
科学コンピューティングとAI
新しいBlackwellのアクセラレータとネットワークは、高度なシミュレーションのパフォーマンスを大幅に向上するとされている。
NVIDIA GB200は、HPC(ハイパフォーマンスコンピューティング)の新時代を切り開く。そのアーキテクチャは、LLMの推論ワークロードを高速化するために最適化された第2世代のTransformer Engineを特長としている。
これにより、1.8兆個のパラメーターを持つGPT-MoE(Generative Pretrained Transformer-Mixture of Experts)モデルなどのリソース集約型アプリケーションで、H100世代と比較して30倍の高速化が実現し、HPCの新たな可能性を切り開く。また、LLMによる大量のデータの処理と解読を可能にすることで、HPCアプリケーションは科学的発見を加速できる貴重なインサイトにより迅速に到達できる。
アメリカ合衆国エネルギー省が管轄しているSandia国立研究所は、並列プログラミング用のLLMコパイロットを構築している。従来のAIは、基本的な逐次コンピューティングコードを効率的に生成できるが、HPCアプリケーション用の並列コンピューティングコードの生成に関して、LLMでは不十分な可能性がある。Sandia国立研究所の研究者は、世界最強のスーパーコンピューターで数万個のプロセッサを利用してタスクを実行するために複数の国立研究所によって設計された専用プログラミング言語であるKokkosで並列コードを自動生成するという大掛かりなプロジェクトでこの問題に果敢に取り組んでいる。
Sandia国立研究所は、情報検索機能と言語生成モデルを組み合わせたRAG(Retrieval-Augmented Generation)というAI技術を利用している。チームはRAGを利用してKokkosデータベースを構築し、AIモデルと統合している。
初期の結果は期待どおりとなっており、Sandia国立研究所のさまざまなRAGアプローチにより、並列コンピューティングアプリケーション用の Kokkosコードが自動生成されることが実証された。Sandiaは、AIベースの並列コードの生成における課題を克服することで、世界中の主要なスーパーコンピューティング施設でのHPCの新たな可能性を切り開こうとしている。他の例として、再生可能エネルギー研究、気候科学、創薬などが挙げられる。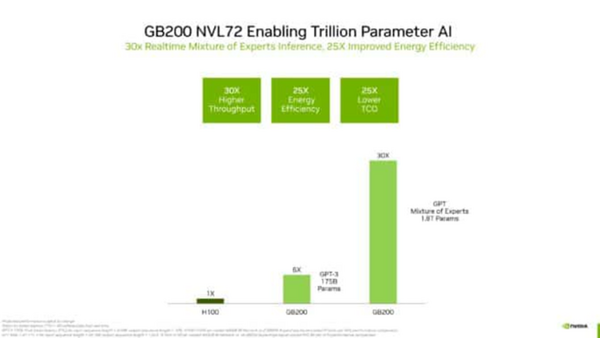
量子コンピューティングの進化の推進
量子コンピューティングは、核融合エネルギー、気象研究、創薬、その他多くの分野の未来を切り開く。そのため、研究者はこれまでにない速さで量子アルゴリズムの開発とテストを行うために、NVIDIA GPUベースのシステムやソフトウェアを使用して、未来の量子コンピューターをシミュレートする作業に尽力している。
NVIDIA CUDA-Qプラットフォームは、CPU、GPU、QPU(量子プロセッシング ユニット)の連携を実現する統一されたプログラミングモデルにより、量子コンピューターのシミュレーションとハイブリッド アプリケーションの開発を可能にする。
NVIDIA Blackwellアーキテクチャは、量子シミュレーションを新たな高みへと導くのに貢献する。また、最新のNVIDIA NVLinkマルチノードインターコネクトテクノロジを利用することで、データ転送が高速化し、量子シミュレーションの高速化が実現する。
科学の飛躍的発展に向けたデータ分析の加速化
RAPIDSを使用したデータ処理は、科学コンピューティングで一般的に行われている。Blackwellは、圧縮データを解凍し、RAPIDSでの分析を高速化するハードウェア解凍エンジンを導入している。
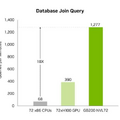
この解凍エンジンは、パフォーマンスを最大800GB/秒まで向上させ、Grace Blackwellがクエリベンチマークにおいて、Sapphire Rapidsの CPUの18倍、NVIDIA H100 TensorコアGPUの6倍速くの処理を可能にする。
このエンジンは、8TB/秒の高メモリ帯域幅とGrace CPUの高速NVLink C2C(Chip-to-Chip)インターコネクトを活用して、データ転送を加速させ、データベースクエリのプロセス全体を高速化する。Blackwellは、データ分析とデータサイエンスのユースケースで卓越したパフォーマンスを発揮し、データの洞察を速め、コストを削減する。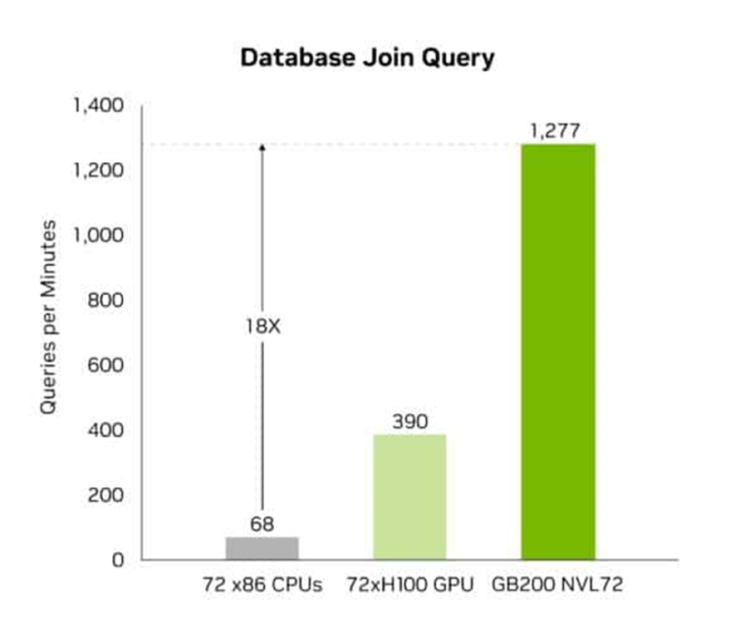
NVIDIA ネットワークによる科学コンピューティングにおける卓越したパフォーマンスの推進
NVIDIA Quantum-X800 InfiniBandネットワークプラットフォームは、科学コンピューティングインフラにおいて最高のスループットを実現する。
これには、NVIDIA Quantum Q3400およびQ3200スイッチとNVIDIA ConnectX-8 SuperNICが含まれており、これらの組み合わせで、前世代の2倍の帯域幅が実現する。Q3400プラットフォームは、NVIDIAのSHARPv4(Scalable Hierarchical Aggregation and Reduction Protocol)を使用して、5倍の帯域幅容量と14.4TflopsのIn-Network Computingを提供し、前世代と比較して9倍の性能向上を実現。
パフォーマンスの飛躍的向上と電力効率の改善により、科学コンピューティングのワークロードの完了時間とエネルギー消費量が大幅に削減させることが可能となる。
NVIDIA 大規模言語モデルと生成AIにも特化した「Blackwell プラットフォーム」とは 性能向上は最大30倍、コスト/エネルギー消費は最大1/25に
NVIDIA 自動運転開発に生成AI対応の「DRIVE Thor」を採用、次世代Blackwellアーキテクチャ搭載 世界最大のEVメーカーBYDとの連携強化/a>
NVIDIAとGoogleが新たに3つのAI協業を発表 DeepMindと連携してLLMを推進 Google PaliGemmaがNVIDIA NIM推論をサポート
日本政府 AIインフラを1,146億円の助成で支援 NVIDIAが国内企業数社と協業、生成AIのインフラ構築「ソブリンAI」強化へ
NVIDIA 関連記事
NVIDIA Japan