NVIDIAはシリコンバレーで3月18日に行った「GTC2024」のNVIDIAの創業者/CEOであるジェンスン フアン(Jensen Huang)氏の期中講演で、従来より高速で規模の大きい演算が求められる生成AIや大規模言語モデルにも特化した「NVIDIA Blackwell」プラットフォームを発表した。新しい「Blackwell GPU」「NVLink」「レジリエンス テクノロジー」によって数兆パラメータ規模のAIモデルを実現し、新しい「Tensor コア」と「TensorRT-LLMコンパイラ」が、LLM推論の運用コストとエネルギーを最大25分の1に削減するという。
「NVIDIA Blackwell」プラットフォームの特徴
2ダイを連結して1基のGPUとして振る舞う「Blackwell GPU」
新しく発表したGPU「Blackwell」はAI性能でAIの学習速度とAI推論を大幅に高速化する。TensorコアFP8とFP4で20PFLOPS、「Transformer Engine」を使った新しいFP4で40PFLOPSの性能を発揮する。これを可能にしている最大の特徴は1パッケージに2ダイを実現したこと。ひと目で巨大化していることが解る。2つのダイを連結すると通常は接続部分がボトルネックとなるが、NVIDIAはそれぞれのダイを10TB/sで接続する技術を採用し、1基のGPUとして動作させても高速性の妨げにならない。あまり強調されてはいないが、この技術は将来、ダイを更に増やすことで容易に高速化を加速できる”可能性”を示唆している。
「Hopper GPU アーキテクチャ」の後継
「NVIDIA Blackwell」は、従来の「Hopper GPU アーキテクチャ」の後継となり、2.5倍の処理速度に向上する。コストとエネルギー消費を従来の25分の1に抑え、数兆パラメータの大規模言語モデルによるリアルタイム生成AIを構築および実行できるようになる。
また、「Blackwell」アーキテクチュアにアップデートし、それを連携することで、自動運転などの「NVIDIA DRIVE」やロボティクスの「Jetson Orin」や、ヒューマノイド向け「Jetson Thor」、ロボティクス・シミュレータ「Isaac」、デジタルツイン「Omniverse」プラットフォームも高速化がはかられる。
Blackwell GPU アーキテクチャは、アクセラレーテッド コンピューティングのための6つの革新的なテクノロジを備えており、データ処理、エンジニアリングシミュレーション、電子設計自動化、コンピューター支援医薬品設計、量子コンピューティング、生成AIなど、NVIDIAにとって新たな業界の機会をすべて解放するブレイクスルーを実現する。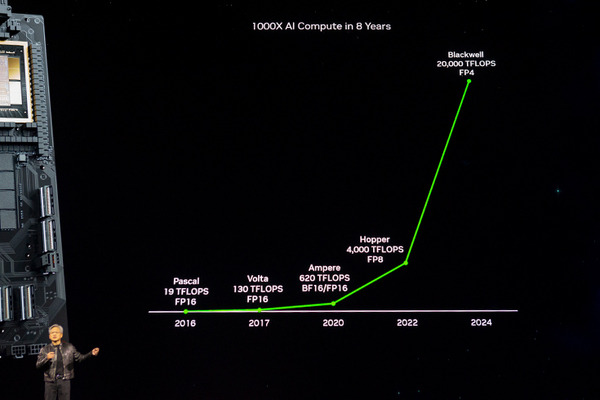
NVIDIAのCEO、ジェンスン フアン氏は次のように述べている。
NVIDIA 創業者/CEO Jensen Huang 氏
私たちは 30 年間、ディープラーニングや AI などの革新的なブレイクスルーを実現することを目標に、アクセラレーテッド コンピューティングを追求してきました。生成 AI は、現代を定義するテクノロジです。Blackwell は、この新たな産業革命を推進するエンジンです。世界で最もダイナミックな企業と協力することで、私たちはあらゆる業界における AI の可能性を実現していくでしょう
Blackwellの由来
ゲーム理論と統計を専門とする数学者であり、米国科学アカデミーに初めて殿堂入りした学者、デビッド ハロルド ブラックウェル(David Harold Blackwell)氏にちなんで名付けられた。前述のとおり、この新しいアーキテクチャは、2年前に発売された現行のNVIDIA Hopperアーキテクチャの後継となる。
アクセラレーテッド コンピューティングと生成AIを推進するBlackwellのイノベーション
Blackwellの6つの革新的なテクノロジが組み合わされることで、最大10兆のパラメータにスケールアップするモデルのAIトレーニングとリアルタイムLLM推論を可能にする。
世界で最も強力なチップ
2,080億のトランジスタを搭載した BlackwellアーキテクチャのGPUは、カスタムビルドの4NP TSMCプロセスを使用して製造されたレチクル リミットのGPUダイを10 TB/秒のチップ間リンクで1つの統合されたGPUに接続している。
第2世代のTransformer Engine
新しいマイクロテンサースケーリングのサポートと、NVIDIA Tensor RTTM-LLMおよびNeMo Megatronフレームワークに統合されたNVIDIAの先進的なダイナミックレンジ管理アルゴリズムにより、Blackwellは新しい4ビット浮動小数点AI推論機能により、コンピューティングとモデルのサイズを2倍にした。
第45世代NVLink
数兆パラメータとMixture of ExpertsのAIモデルのパフォーマンスを加速するために、NVIDIA NVLinkの最新バージョンはGPUあたり1.8TB/秒の革新的な双方向スループットを実現し、最も複雑なLLM向けに最大576基のGPU間のシームレスで高速な通信を保証する。
RAS Engine
Blackwell搭載GPUには、信頼性、可用性、保守性を高めるための専用エンジンが含まれている。さらに、Blackwellアーキテクチャは、AIベースの予防保守を利用するチップレベルの機能を追加し、診断を実行し、信頼性の問題を予測。これにより、システムの稼働時間が最大化され、大規模なAI展開の回復力が向上し、一度に数週間、場合によっては数か月にわたって中断なく実行され、運用コストを削減できる。
セキュア AI
高度なコンフィデンシャル コンピューティング機能は、新しいネイティブ インターフェイス暗号化プロトコルのサポートにより、パフォーマンスを損なうことなくAIモデルと顧客データを保護する。これは、ヘルスケアや金融サービスなどのプライバシーに敏感な業界にとって重要だ。
解凍エンジン
専用の解凍エンジンは最新の形式をサポートし、データベース クエリを高速化し、データ解析とデータサイエンスで最高のパフォーマンスを実現。今後数年間で、企業が年間数百億ドルを費やすデータ処理は、GPU による高速化がさらに進むと予想される。
巨大なスーパーチップ
NVIDIA GB200 Grace Blackwell Superchipは、900 GB/秒の超低消費電力のNVLinkのチップ間インターコネクトを介して、2つのNVIDIA B200 TensorコアGPUをNVIDIA Grace CPUに接続。GB200 Superchipは、LLM推論ワークロードに対してNVIDIA H100 Tensor コア GPUと比較して最大30倍のパフォーマンス向上を実現し、コストとエネルギー消費を最大25倍削減する。なお、最高のAIパフォーマンスを実現するために、GB200 搭載システムは、同じく本日発表されたNVIDIA Quantum-X800 InfiniBand および Spectrum-X800イーサネットプラットフォームに接続でき、最大 800Gb/秒の速度で高度なネットワーキングを実現する。
「GB200」性能向上は最大30倍、コスト/エネルギー消費は最大1/25に
GB200は、最も計算集約的なワークロード向けのマルチノード水冷ラックスケール システムであるNVIDIA GB200 NVL72の主要コンポーネントだ。これは、72基のBlackwell GPUと36基のGrace CPUを含む36基のGrace Blackwell Superchipを組み合わせており、第5世代NVLinkによって相互接続する。
さらに、GB200 NVL72には、NVIDIA BlueField-3データプロセッシングユニットが含まれており、ハイパースケールAIクラウドでのクラウドネットワークアクセラレーション、コンポーザブルストレージ、ゼロトラスト セキュリティ、GPUコンピューティングの弾力性を実現する。GB200 NVL72は、LLM推論ワークロードにおいて、同数のNVIDIA H100 TensorコアGPUと比較して最大30倍の性能向上を実現し、コストとエネルギー消費を最大25倍削減する。
このプラットフォームは、1.4エクサフロップスのAIパフォーマンスと30TBの高速メモリを備えた単一のGPUとして機能し、最新のDGX SuperPODの構成要素だ。NVIDIAは、NVLinkを通じて8つのB200 GPUをリンクし、x86ベースの生成AIプラットフォームをサポートするサーバーボードであるHGX B200を提供。HGX B200は、NVIDIA Quantum-2 InfiniBandおよび Spectrum-X イーサネット ネットワーキング プラットフォームを通じて、最大400Gb/秒のネットワーキング速度をサポートする。
Blackwellパートナーのグローバルネットワーク
Blackwellベースの製品は、今年後半からパートナー各社から提供される予定だ。
AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructure
Blackwellは、AWS、Google Cloud、Microsoft Azure、Oracle Cloud Infrastructureから提供される。NVIDIAクラウド パートナープログラム企業であるApplied Digital、CoreWeave、Crusoe、IBM Cloud、Lambdaと同様に、Blackwellを利用したインスタンスを提供する最初のクラウドサービス プロバイダーになる。
ソブリンAIクラウドも、Blackwellベースのクラウド サービスとインフラストラクチャも提供する予定となっている。これには、Indosat Ooredoo Hutchinson、Nebius、Nexgen Cloud、Oracle EU Sovereign Cloud、Oracle US、UK、Australian Government Clouds、Scaleway、Singtel、Northern Data GroupのTaiga Cloud、Yotta Data ServicesのShakti CloudとYTL Power Internationalが含まれている。GB200は、大手クラウドサービスプロバイダーと共同設計されたAIプラットフォームである NVIDIA DGX Cloudでも利用可能になる。これにより、企業の開発者は、高度な生成AIモデルの構築と展開に必要なインフラストラクチャとソフトウェアへの専用アクセスができるようになる。
今年後半に新しい NVIDIA Grace Blackwell ベースのインスタンスをホストする予定だ。
Cisco、Hewlett Packard Enterprise、Lenovo、Supermicro
Aivres、ASRock Rack、ASUS、Eviden、Foxconn、GIGABYTE、Inventec、Pegatron、QCT、Wistron、WiwynnそしてZT Systemsと同様に、Blackwell製品をベースにした幅広いサーバーを提供する予定だ。さらに、エンジニアリング シミュレーションの世界的リーダーであるAnsys、Cadence、Synopsysを含むソフトウェアメーカーのネットワークが拡大しており、Blackwellベースのプロセッサを使用して、電気、機械、製造システムと部品の設計とシミュレーション用のソフトウェアが高速化される予定だ。顧客は生成AIとアクセラレーテッドコンピューティングを使用して、より迅速に、より低コストで、より高いエネルギー効率で製品を市場に投入できる。
NVIDIAソフトウェアのサポート
Blackwell製品ポートフォリオは、プロダクショングレードのAI向けのエンドツーエンド オペレーティング システムであるNVIDIA AI Enterpriseによってサポートされている。NVIDIA AI Enterprise には、同じく本日発表されたNVIDIA NIM推論マイクロサービスのほか、企業がNVIDIAで高速化されたクラウド、データセンター、ワークステーションに導入できるAIフレームワーク、ライブラリ、ツールが含まれている。
NVIDIA 自動運転開発環境に生成AI対応の次世代Blackwellアーキテクチャ搭載「DRIVE Thor」を採用 世界最大のEVメーカーBYDとの連携強化
NVIDIA ヒューマノイド・マニピュレータ・自動搬送ロボット向けに「Isaacのメジャーアップデート」を発表 安川電機が「GTC 2024」でデモ展示
NVIDIAがヒューマノイド開発プラットフォーム提供を発表 ディズニーの二足歩行ロボットが登壇 Jetson Orinから次世代Thorへ
VIDIAが量子コンピュータ開発を支援する「NVIDIA Quantum Cloud」開始 暗号化にGPUの並列処理を活用する「cuPQC」も
「GTC 2024」展示ホールはヒューマノイドなど次世代の情報を求めて超満員 現地の様子を写真と動画で体験
いよいよ明日開幕!世界最大級のAIとGPUイベント「NVIDIA GTC 2024」現地直前レポート、サンノゼの青空の下で
世界最大級のAIとGPUイベント「NVIDIA GTC 2024」リアル/オンラインで開催 GTCの全容と日本から参加できる見どころ徹底解説
NVIDIA 日本向けイベント「Japan AI Day」3/22にオンライン開催 生成AI・LLM・デジタルツイン・エッジAIなど12講演 大手企業も登壇
NVIDIA GTC2024関連記事(ロボスタ)